- 저번 주 이야기
- 우리는 왜 일하는가?
- 어떻게 해야 일을 더 잘할 수 있을까?
- 번아웃
- 맥북 스마트하게 사용하기
- 숙제 하신분..^_^?
저번 주 숙제¶
- 자신이 "왜" 일하는지 생각해보기
- DM으로 주셔도 좋고, 안주셔도 좋고
- Mac을 더 스마트하게 사용하기 위한 도구 설치
- 제가 알려드린 것 말고도 많음
- 맥 생산성 도구 이런 내용으로 검색해보고 설치
올바른 자세¶
- 자세 정말 중요합니다!
- 사실 전 아파봤어요 ㅠ.. 그 후 물건에 투자를 잘 함(아파봐야... 알더라..)
- 개발자가 자주 아픈 부위
- 허리
- 목
- 어깨
- 손목
- 미리 신경쓰고 예방합시다
- 단, 모든 것은 사람마다 케바케(신체 구조, 근육량 등에 따라 다름)
- 제 이야기를 듣고 여러분만의 자세를 찾아보세용 :)
- 카일이 사용하는 도구
- 의자
- 책상
- 모니터
- 노트북 받침
- 키보드, 마우스
의자¶
- 의자 구입시 고려하는 부분
- 1) 높이 조절 가능한지? : 자세(허리)와 직결됨
- 2) 의자 높이 조절 가능한지? : 자세(허리)와 직결됨
- 3) 팔걸이 조절 가능한지? : 자세(손목, 어깨)와 직결됨 => 의자 팔걸이와 키보드 높이를 거의 일직선으로 맞춤
- 4) 본인이 앉았을 때 편한지? : 결국 이게 중요! 의자는 꼭 앉아보고 사야..
- 사용하고 있는 의자
- 시디즈 T50 Air : 약 35~50만원
- 시디즈 T50 Air : 약 35~50만원

- 좋았던 의자
- 허먼밀러 에어론 : 약 100만원
- 허먼밀러 에어론 : 약 100만원

- 앤드류가 사용하시는 의자
- 한샘 피카소 : 약 43~50만원
- 한샘 피카소 : 약 43~50만원

책상¶
- 책상 구입시 고려할 부분
- (의자를 조절한 후) 책상 높이가 나와 맞는가?
- 모니터를 뒤로 둘만한 공간이 있는가
- (집에서 쓴다면) 사용할 물건들을 놓을만큼 넓은가?
- 스탠딩이 가능한가?
- 사용하고 있는 책상
- 데스커 스탠딩 책상(1400*700) : 약 78만원
- 주로 서서 일함

- 데스커 스탠딩 책상(1400*700) : 약 78만원
- 사용했던 책상
- 데스커 컴퓨터 책상(1200*600) : 약 13만원
- 무난한 책상!

- 데스커 컴퓨터 책상(1200*600) : 약 13만원
- 스탠딩이 좀 비싸죠.. 타협해서 이런 제품도 괜찮음
- 제가 구입해서 쏘카 데이터 그룹에 셋팅해둔 책상
- 루나랩 스탠딩 책상(수동 : 16만원, 버튼식 : 20만원)

모니터¶
- 모니터 구입시 고려하는 부분
- 화질 : 맥북은 4K, UHD 모니터 쓰면 저는 눈이 아파요..
- 모니터 높이 조절 가능 유무 : 높이 조절이 가능해야 목, 어깨에 좋음(조절 불가능하면 책을 쌓아도 됨)
- 모니터 틸트 가능 유무 : 앞뒤로 조절 가능한지
- 모니터 피벗 가능 유무 : 세로로 사용할 수 있는지
- 기타 기능성
- 모니터 올바른 높이
- 사람마다 다르고, 모니터 크기에 따라 다르긴한데.. 저는 크롬 URL창이 눈가에 가도록 설정(다른 분들은 높게 쓰거나 낮게 씀)
- 모니터와 거리
- 팔을 뻗어서 달랑말랑한 거리
- 집에서 LG 27 UK850 사용 중
- 약 80만원
- 현재 절판인데, LG쪽이 모니터 좋음(USB C로 모니터 연결하면 맥북 충전도 자동으로 됨)
- 후기 글
- 회사에선 크로스오버 2714UD 4K 사용 중
- 약 30만원
- 현재 절판인데, 크로스오버<- 쪽이 가성비 좋음
노트북 받침¶
- 노트북만 사용하시지 말고, 이왕이면 키보드 + 마우스를 꼭 같이 쓰세요
- 노트북 쓰면 자세가.. ㅠ_ㅠ
- 그리고 노트북을 왼쪽에 둘지, 오른쪽에 둘지도 고민해보면 좋음

키보드¶
- 키보드는 왠만하면 구입해서 사용하는 것을 추천
- 키보드 선택시 고려할 포인트
- 소음(청축, 적축, 갈축, 흑축) : 청축을 사무실에서 쓰면..ㅎㅎㅎ;
- 키보드의 높이 : 기계식 키보드 대부분 높이감이 있음. 본인의 손목에 무리가 갈 수 있으니 주의 => 높다면 키보드 받침대, 팜레스트 구입 추천
- 손목과 잘 맞는지 중요
- 타이핑의 즐거움에 따라 내 업무 능률이 오르는가
- 저는 낮은 높이를 선호해서 애플의 매직 키보드를 사용합니다
- 해피해킹, 리얼포스, 레오폴드 등을 많이 사용하는 편
마우스¶
- 키보드를 사용하고 마우스를 쓰지 않으면, 좋지 않은 자세로 귀결됨
- 맥에서 매직마우스를 사용하면 터치패드 기능(손가락 3개 이동 등)을 사용할 수 있어 저는 좋아하지만, 손목에 무리가 온다는 분도 봄
- 트랙패드도 대안 중 하나인데, 저는 트랙패드가 손목에 무리를 줘서 굳이 사용하지 않음
- 손목 터널 증후군이 온다면 버티컬 마우스 + 손목 받침대 추천
- 손목 터널 증후군 : 손목이 찌릿찌릿하고 저린 경우
정리¶
- 자세는 지금부터 잘 잡아놔야 함
- 혹시 "아 카일은 다 비싼거 쓰네. 돈이 많나요" 생각하신다면 => X
- 아파서 병원에 쓴 돈이 더 많아요.. 그 이후에 아프기 싫어서 씀
- 이건 나이가 들면 나중에 느낄듯.. 보통 30될 쯤 아파서 병원에 돈 많이 쓰는 경우를 꽤 봄
- 지금 무리해서 많은 것을 구입하는 것보다 하나씩 구입하는 것을 추천
- 예 : 키보드부터 구입, 모니터 등등
- 사람마다 결국 다르기 때문에 참고만 하고 자신만의 자세 찾아보기
- 적절한 스트레칭과 운동!
- (아 영양제도 먹어야 좋은데.. 이건 나중에)
정리¶
- 동영상 중 제 생각과 비슷한 유튜브 영상
- 바른자세와 체형을 위한 책상과 의자의 인체공학적 세팅
- 의자 : 1분 22초 ~ 3분 16초
- 책상 : 3분 19초 ~ 5분
- 모니터 : 5분 15초 ~ 6분 30초
- 노트북 : 6분 30초 ~ 7분 10초
- 영상 찍으신 분은 키보드, 마우스는 고려하기 힘들다 하지만.. 개발자는 더 고려하면 좋을듯
Pandas 퀵리뷰¶
- BigQuery vs Pandas 언제 사용할까?
- New York Taxi Data 소개 및 Pandas 자주 사용하는 Method 리뷰
- Anti Pattern
BigQuery vs Pandas 언제 사용할까?¶
- BigQuery(SQL)을 취업 전에 사용할 일이 적어서, 보통 데이터 전처리를 Pandas로만 해온 분이 많음
- BigQuery의 장점
- 빠른 퍼포먼스
- 관리의 필요성이 적음
- Pandas의 장점
- Python으로 처리 가능
- 적은 데이터의 경우 쉽게 가능
- 현실
- 데이터는 Database에 저장됨
- Database에서 => Local 혹은 Server로 옮길 때 발생하는 IO(시간) 고려해야 함
- 일단 Database에서 통째로 (ex: SELECT * FROM Table) 가져오려면 무지막지한 시간이 걸림
- 적절한 조합이 필요
- BigQuery에서 원본 데이터를 가공 및 집계(Aggregate)
- BigQuery 내부적으로 1000개 이상의 CPU를 사용해 데이터를 처리함
- Row 수가 감소되는 것을 압축한다고 생각할 수 있는데, 압축한 후 Local 혹은 Server로 옮겨옴
- 압축(혹은 집계) 하는 과정에서 여러 Feature를 생성할 수 있음
- DATETIME 처리 : DATETIME_TRUNC 함수
- Reverse Geocoding : BigQuery GIS 활용
- 1시간 전 값, 2시간 전 값 등 : LAG 함수
- BigQuery에서 처리하기 조금 까다로운 것
- One Hot Encoding, Label Encoding
- Python에서 진행
- BigQuery에서 원본 데이터를 가공 및 집계(Aggregate)

New York Taxi Data 소개 및 Pandas 자주 사용하는 Method 리뷰¶
- BigQuery에 Open 데이터가 존재함
bigquery-public-data:new_york_taxi_trips- 그 중에서도 tlc_yello_trips_2015 사용할 예정

In [1]:
# !pip3 install pandas-gbq
project_id = 'your_project_id'
- 1) pd.read_gbq
- BigQuery 데이터를 쿼리 날려서 로컬에서 불러올 수 있음
- reauth=True, auth_local_webserver=True로 주면 웹에서 인증함
- 이 과정이 없다면 별도의 credential_key를 발급해서 지정해야 함
In [2]:
import pandas as pd
import numpy as np
query = """
SELECT
DATETIME_TRUNC(pickup_datetime, hour) as pickup_hour,
count(*) as cnt
FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2015`
WHERE EXTRACT(MONTH from pickup_datetime) = 1
GROUP BY pickup_hour
ORDER BY pickup_hour
"""
df = pd.read_gbq(query=query, dialect='standard',
project_id=project_id,
reauth=True,
auth_local_webserver=True)
In [3]:
df.tail()
Out[3]:
- 2) 컬럼의 타입을 변경해 메모리 사용량 줄이기
- df.info()
- 각 컬럼의 타입에 대한 정보 제공
- 메모리 사용량도 제공
In [4]:
df.info()
- int64보다 int32가 메모리 사용량 관점에서 좋습니다
- object보단 category가 빠름
In [8]:
def reduce_mem_usage(df):
"""
iterate through all the columns of a dataframe and
modify the data type to reduce memory usage.
"""
start_mem = df.memory_usage().sum() / 1024**2
print(f'Memory usage of dataframe is {start_mem:.2f}MB')
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max <\
np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max <\
np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max <\
np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max <\
np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
elif str(col_type)[:5] == 'float':
if c_min > np.finfo(np.float16).min and c_max <\
np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max <\
np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
pass
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print(f'Memory usage after optimization is: {end_mem:.2f}MB')
print(f'Decreased by {100*((start_mem - end_mem)/start_mem):.1f}%')
return df
In [9]:
new_df = reduce_mem_usage(df)
In [10]:
new_df.info()
# 11.7KB -> 8.8KB, 데이터가 작아서 이렇고 데이터가 많다면 효과는 더 좋겠죠?
- 3) 컬럼별 몇개의 값이 있는지 Count
- value_counts()
- 카테고리컬 값이 몇개 있는지 count
df['col_name'].value_counts(ascending=True)
In [11]:
# 사실 여기선 이미 BigQuery에서 counts하고 옴. 하지만 다른 경우 유용하게 사용
new_df['pickup_hour'].value_counts().head()
Out[11]:
- 4) Python에서 DATETIME EXTRACT
- year, month, day, hour
- 일단 datetime 타입인지 확인 => 맞다면 df['col_name'].dt로 접근 가능
In [12]:
new_df['pickup_hour'].dt
Out[12]:
In [13]:
new_df['year'] = new_df['pickup_hour'].dt.year
new_df['month'] = new_df['pickup_hour'].dt.month
new_df['day'] = new_df['pickup_hour'].dt.day
new_df['hour'] = new_df['pickup_hour'].dt.hour
new_df['weekday'] = new_df['pickup_hour'].dt.weekday
- 5) 특정 조건에 맞는 데이터 Filtering
- 1월 10일 오전 10시 데이터가 궁금하다면?
- ㄱ. df[특정 조건][특정 조건]
- UserWarning이 발생
In [14]:
%%timeit 100
new_df[new_df['month'] == 1][new_df['day'] == 10][new_df['hour']==10]
- ㄴ. df[ (T or F가 나오는 연산) & (T or F가 나오는 연산) ]
- 괄호 안에 T or F가 나오는 것을 연결
- 논리곱에 대해 이해하면 좋음. 위키피디아
- True * True => True
- True * False => False
- False * False => False
- Pandas에서 괄호 사이에 &를 사용해 연산함
- 번역 : 각 연산에서 모두 True가 나오는 값만 필터링해오겠다
In [15]:
%%timeit 100
new_df[(new_df['month'] == 1) & (new_df['day']==10) & (new_df['hour']==10)]
- ㄷ. loc 사용
- loc와 iloc를 알아두면 좋음(예전엔 .ix도 있었는데 없어진다고 하네요)
- loc : 컬럼명 기준으로 처리할 경우
- iloc : index 기준으로 처리할 경우(숫자)
In [16]:
new_df.loc[new_df['day'].isin(['10', '11'])].head()
Out[16]:
In [17]:
%%timeit 100
new_df.loc[(new_df['month']==1) & (new_df['day']== 10)].head()
- ㄹ. query 사용
- 쿼리 날리는 방식처럼 사용 가능
In [18]:
%%timeit 100
new_df.query('month == 1 & day == 10').head()
- 더 궁금하다면
- 6) Pivot Table
- pivot이 있고 pivot_table이 있음
- pivot_table이 더 high level
- groupby와 unstack을 사용해도 동일한 결과를 얻을 수 있음
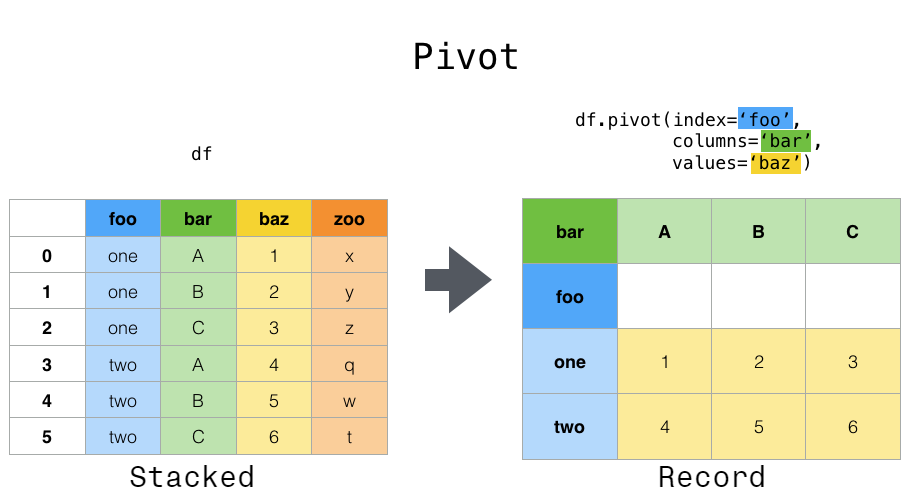
- pivot_table은 위 결과에서 aggfunc(집계)를 진행
In [19]:
df.pivot_table('cnt', index='hour', columns='weekday', aggfunc='mean').head()
Out[19]:
In [20]:
df.groupby(['hour', 'weekday'])['cnt'].mean().unstack().head()
Out[20]:
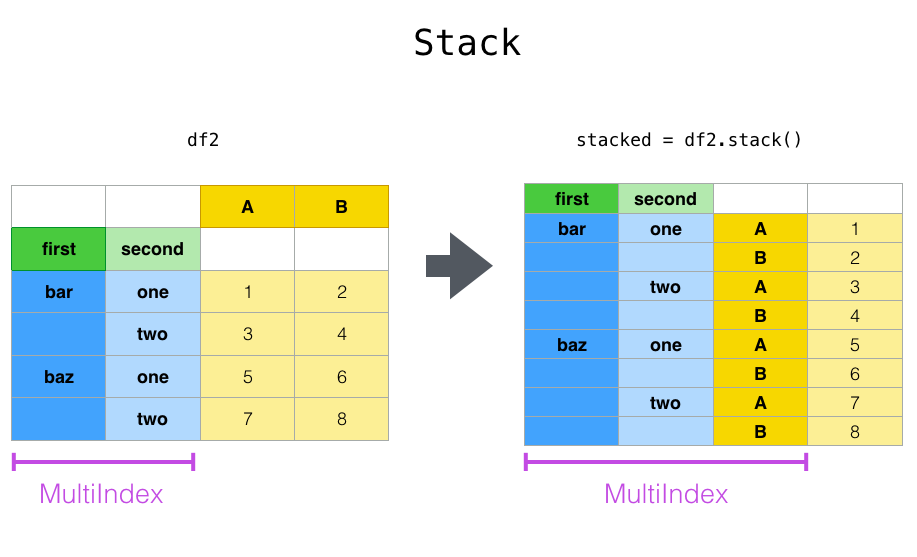
- 7) 재구조화하는 다양한 방식
- stack(), unstack()
- melt()
- .reset_index() 등을 사용하면 결국 비슷한 결과가 나오기도 함
- pydata document 참고하면 자세한 정보 존재
- stack() : 쌓다. 위 아래로 변경함. Row로 쭈욱 펼쳐진 상태
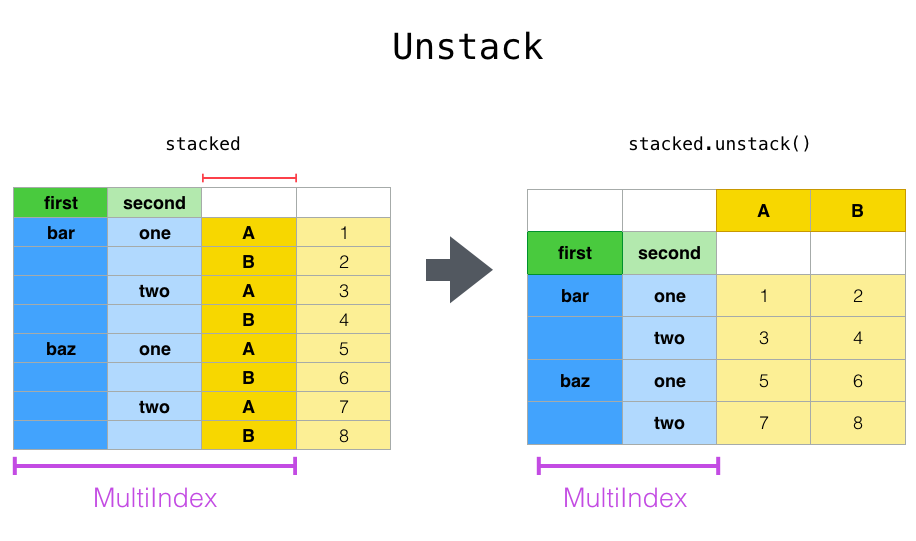
- unstack() : Column으로 넓어진 상태
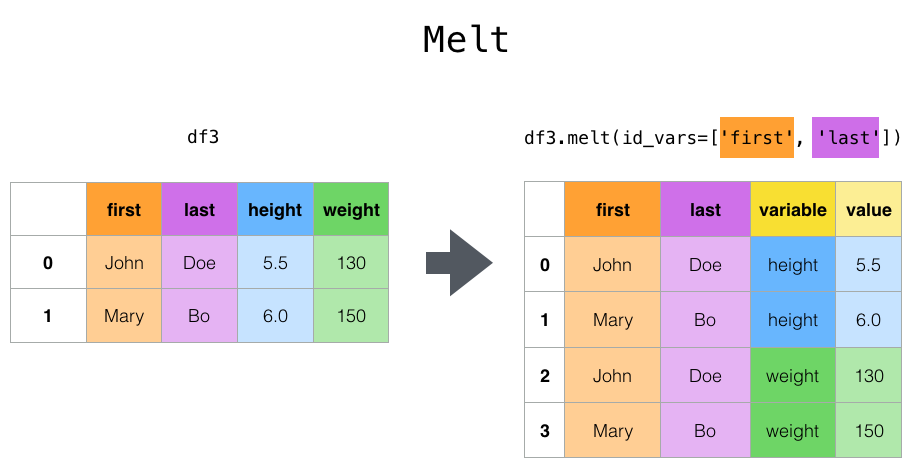
- melt() : Unpivot, id_vars 인자로 지정해주는 것은 그대로 유지
- 8) 날짜 더미 데이터 생성하기
- pd.date_range() 사용
In [21]:
pd.date_range(start='2018-01-01', end='2019-01-01', freq='1H')
Out[21]:
In [22]:
pd.date_range(start='2018-01-01', end='2019-01-01', freq='1D')
Out[22]:
- 9) String Value에 특정 단어가 포함되는지
- df['col_name'].str.contains 사용
In [23]:
# 이번 데이터셋엔 str 값이 없으므로.. hour를 임시로 str로 바꾸고 써볼게요
new_df['string_hour'] = new_df['hour'].astype(str)
# 여러 조건일 경우 | 사용
new_df.loc[new_df['string_hour'].str.contains("10|11")==True].head()
Out[23]:
- 10) 이동 평균 및 Lag
- 이동 평균
- Series.rolling() 사용
- datetime64 타입을 지정해서 사용하면 NotImplementedError 발생
- 이럴 경우 set_index()로 인덱스 지정하고 사용
- Lag 함수
- Series.shift() 사용
- 이동 평균
In [24]:
new_df = new_df.set_index('pickup_hour')
new_df['moving_average'] = new_df['cnt'].rolling(window=3, center=False).mean()
new_df['lag_cnt'] = new_df['cnt'].shift(1)
new_df.head()
Out[24]:
- 11) fillna, merge, concat 등
- fillna : na값 채우기
- merge : SQL의 join과 비슷
- concat : axis=1, axis=0으로 붙이기
- 공식 문서 참고..!
- 12) Notebook Setting
- 한번쯤 찾아보는 옵션들
- Document 참고
In [25]:
# display max row 설정
pd.set_option('display.max_rows', 1000)
# Plot 그릴시 레티나로 그리기(Mac에서 더 또렷하게)
%config InlineBackend.figure_format = 'retina'
# 이걸 설정하면 한 셀에서 Multiple Output Print 가능
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
Pandas Anti Pattern¶
- 오성우님의 뚱뚱하고 굼뜬 판다(Pandas)를 위한 효과적인 다이어트 전략 필독 :)
- 전 딱 하나만 강조
- For-loop을 사용하지 말고, Vectorization 사용하자
- pd.apply(), pd.iterrows()는 왠만하면.. 사용하지 말자
- %%timeit 등을 찍어보며 퍼포먼스를 비교해보자
정리¶
- 1) Pandas + BigQuery => pd.read_gbq()
- 2) 컬럼 타입 변경 => Memory 사용량 감소
- 3) 컬럼별 값이 얼마나 있는지 => value_counts()
- 4) Datetime 추출하고 싶은 경우 => df['datetime_column'].dt.~~~
- 5) Filtering
- df[특정 조건][특정 조건]
- df[ (T or F가 나오는 연산) & (T or F가 나오는 연산) ]
- loc 사용
- query 사용
- 6) Pivot Table
- 7) 재구조화 : stack(), unstack(), melt(), .reset_index()
- 8) 날짜 더미 데이터 생성 : pd.data_range()
- 9) String value 확인 : df['col_name'].str.contains()
- 10) 이동 평균 : Series.rolling, 이전 값(Lag) : Series.shift()
- 11) 기타 : fillna, merge, concat
- 12) notebook setting
- 13) Pandas Anti Pattern을 피합시다! : pd.apply(), pd.iterrows() 사용은 고민해보고 결정하기
데이터 시각화¶
- 시각화하는 방식은 매우 많음
- Python에서 데이터 시각화하는 다양한 방법 참고
- Tableau를 사용하면 편하긴 하지만, 비싼 편이고 데이터 작업할 땐 불편한 경우도 있음 => Python으로도 어느정도 할 줄 알아야!
- 전 Matplotlib을 사용하기보다, Dataframe.plot()을 사용하는 편 => .plot() 내부에서 matplotlib 사용함
- 단, Matplotlib에 없는 heatmap, factorplot, boxplot 등은 seaborn에서 사용
- ggplot 스타일이 이뻐서 ggplot으로 셋팅해 사용
- 동적으로 데이터 확인하고 싶은 경우 cufflinks 사용
- cufflinks는 plotly wrapper
- 정적 그래프와 동적 그래프 각각의 장단점이 있음
- 보통 동적 그래프가 무조건 좋다 생각하겠지만, 데이터가 많으면 처리량이 많아 터짐
- 정적 그래프 + ipywidget으로 동적 처리하는 방법도 있음
- 필요한 라이브러리 설치
In [31]:
# !pip3 install cufflinks==0.16
# !pip3 install plotly==3.10.0
# !pip3 install seaborn
In [26]:
import plotly.plotly as py
import cufflinks as cf
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.style.use('ggplot')
print(cf.__version__)
%config InlineBackend.figure_format = 'retina'
cf.go_offline()
In [27]:
%%time
query = """
SELECT
DATETIME_TRUNC(pickup_datetime, hour) as pickup_hour,
count(*) as cnt
FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2015`
WHERE EXTRACT(MONTH from pickup_datetime) = 1
GROUP BY pickup_hour
ORDER BY pickup_hour
"""
df = pd.read_gbq(query=query, dialect='standard', project_id=project_id)
공통점¶
- 하나의 Figure(그림, 도화지 느낌)에
여러 그래프를 그리고 싶은 경우 아래의 형태로 변환해야 함- groupby 후, unstack(), stack(), melt() 등 활용
| index | column_a | column_b | column_c
| 1 | 1000 | 1500 | 1200
| 2 | 1400 | 1000 | 1200
| 3 | 1800 | 800 | 1200In [28]:
# pickup_hour가 이미 datetime이라 아래 to_datetime은 안해도 되지만,
# 혹시 필요하신 분을 위해 남겨둠
# df['pickup_hour'] = pd.to_datetime(df['pickup_hour'])
df = df.set_index('pickup_hour')
In [29]:
df.head()
Out[29]:
In [30]:
layout1 = cf.Layout(
height=500,
width=800
)
df.iplot(kind='scatter',xTitle='Datetimes',yTitle='Demand',title='NYC Taxi Demand(2015-01)', layout=layout1)
In [31]:
# 그냥 plot 사용시
df.plot(kind='line', figsize=(12, 5));

In [32]:
df['date'] = df.index.date
df.groupby(['date'])[['cnt']].sum().head()
Out[32]:
In [33]:
df.groupby(['date'])[['cnt']].sum().iplot(layout=layout1)
In [34]:
df.groupby(['date'])[['cnt']].sum().plot(kind='line', figsize=(12, 5));

In [35]:
# Feature Engineering
df['weekday'] = df.index.weekday
df['hour'] = df.index.hour
df['weeknum'] = df.index.week
df['is_weekend'] = ((pd.DatetimeIndex(df.index).dayofweek) // 5 == 1).astype(int)
In [36]:
df.groupby('hour')[['cnt']].sum().head(5)
Out[36]:
In [37]:
df.groupby('hour')[['cnt']].sum().iplot(layout=layout1)
In [38]:
df.groupby('hour')['cnt'].sum().plot(x='hour', y='cnt', kind='line', style="-o", figsize=(15,5));

In [39]:
# Heatmap은 보통 Interactive가 필요 없어서 seaborn 사용하는걸 추천
plt.figure(figsize=(12,8))
sns.heatmap(df.groupby(['hour', 'weekday'])['cnt'].mean().unstack(),
lw=.5, annot=True, cmap='GnBu', fmt='g', annot_kws={'size':10});

In [40]:
df.groupby(['hour', 'weekday'])[['cnt']].mean().head(10)
Out[40]:
In [41]:
df.groupby(['hour', 'weekday'])['cnt'].mean().unstack().head(3)
Out[41]:
In [42]:
average_df = df.groupby(['is_weekend', 'hour']).mean()['cnt'].\
unstack(level=0).rename(columns={0:"weekday", 1:"weekend"})
In [43]:
average_df.iplot(layout=layout1)
In [44]:
sns.lineplot(data=average_df);

In [45]:
df.groupby(['weekday','hour'])[['cnt']].sum().head()
Out[45]:
In [46]:
# 아마 이걸 원하시진 않으셨을듯
df.groupby(['weekday','hour'])[['cnt']].sum().plot();

In [47]:
df.groupby(['weekday','hour'])['cnt'].sum().unstack(level=0).head(5)
Out[47]:
In [48]:
df.groupby(['weekday','hour'])['cnt'].sum().unstack(level=0).plot();

In [49]:
# reset_index()는 왜 하나요?
df.groupby(['weekday', 'hour']).mean()['cnt'].unstack(level=0).\
melt(id_vars="hour", value_vars=[0,1,2,3,4,5,6], value_name='cnt').head(5)
Out[49]:
In [50]:
# melt는 index를 인식 못함
df.groupby(['weekday', 'hour']).mean()['cnt'].unstack(level=0).reset_index().\
melt(id_vars="hour", value_vars=[0,1,2,3,4,5,6], value_name='cnt').head(5)
Out[50]:
In [51]:
# factor plot은 df.groupby(['weekday','hour'])['cnt'].sum().unstack(level=0).head(5)와 input 데이터 형태가 다름
data = df.groupby(['weekday', 'hour']).mean()['cnt'].unstack(level=0).reset_index()
data = data.melt(id_vars="hour", value_vars=[0,1,2,3,4,5,6], value_name='cnt')
sns.factorplot(x="hour", y='cnt', hue="weekday", data=data, height=5, aspect=3);

In [52]:
plt.figure(figsize=(16, 6));
sns.boxplot(x='hour', y='cnt', data=df);
plt.title("Hourly Box Plot(2015-01 Data)");

In [53]:
def visualize_hourly_boxplot_by_weeknum(df, y, weeknum):
plt.figure(figsize=(16, 6));
sns.boxplot(x='hour', y=y, data=df[df['weeknum']==weeknum]);
plt.title(f"Hourly Box Plot(2015-{weeknum:02} Data)");
In [54]:
for week in range(1, 3):
visualize_hourly_boxplot_by_weeknum(df, 'cnt', week)


Ipywidget을 활용한 인터랙티브 시각화¶
- ipywidget은 Jupyter Notebook에서 Interactive하게 도와주는 도구
- 시각화할 때 사용할 수 있고, 데이터 추출할 때 등 활용할 수 있음
- 간단히 생각하면 버튼을 만든다고 보면 됨
In [55]:
import ipywidgets as widgets
from ipywidgets import interact
# 이걸 설정하면 Multiple Output이 가능함
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
In [56]:
def f(x):
return x
interact(f, x=10);

In [57]:
interact(f, x=widgets.IntSlider(min=-10, max=30, step=1, value=10));
In [58]:
interact(f, x=['apples','oranges']);

In [59]:
@interact(x=True, y=1.0)
def g(x, y):
return (x, y)

In [60]:
df.head()
Out[60]:
In [61]:
def visualize_by_date(df):
def view_images(date):
data = df.loc[df['date'] == date]['cnt']
ax = data.plot();
ax.set_title(f'date is {date}')
interact(view_images, date=list(np.sort(df['date'].unique())))
In [62]:
visualize_by_date(df)

Pydeck¶
- 지도 데이터 시각화 : Uber의 pydeck 사용하기
- 지도 데이터 시각화할 때 제일 좋다고 생각하는 라이브러리
- 더 쉽게 사용하려면 Kepler.gl를 사용해도 좋음(웹 UI 존재)
- MAPBOX_API_KEY를 꼭 등록하고 진행해야 됩니다!
- 사용 방법
- 1) 데이터 준비(Pandas Dataframe, 좌표 존재하거나 h3 index 필요)
- 2) Layer 선택
- 어떤 그래프를 그릴지
- 3) ViewState 정의
- 어떤 시각에서 볼 것인지(좌표, Zoom Level, bearing 등)
- 4) Deck 객체 생성하며 Layer, ViewState 연결
- r = pdk.Deck(layers=[layer], initial_view_state=view_state)
- 5) 렌더링
- r.show()
- 6) 필요시 Deck 객체에 Layer 데이터 업데이트
- r.update()
In [ ]:
!pip3 install pydeck
!jupyter nbextension install --sys-prefix --symlink --overwrite --py pydeck
!jupyter nbextension enable --sys-prefix --py pydeck
# 그 후 노트북, 터미널 껐다 키기
In [63]:
import pydeck as pdk
In [64]:
%%time
agg_query = """
WITH base_data AS
(
SELECT
nyc_taxi.*,
pickup.zip_code as pickup_zip_code,
pickup.internal_point_lat as pickup_zip_code_lat,
pickup.internal_point_lon as pickup_zip_code_lon,
dropoff.zip_code as dropoff_zip_code,
dropoff.internal_point_lat as dropoff_zip_code_lat,
dropoff.internal_point_lon as dropoff_zip_code_lon
FROM (
SELECT *
FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2015`
WHERE
EXTRACT(MONTH from pickup_datetime) = 1
and pickup_latitude <= 90 and pickup_latitude >= -90
and dropoff_latitude <= 90 and dropoff_latitude >= -90
) AS nyc_taxi
JOIN (
SELECT zip_code, state_code, state_name, city, county, zip_code_geom, internal_point_lat, internal_point_lon
FROM `bigquery-public-data.geo_us_boundaries.zip_codes`
WHERE state_code='NY'
) AS pickup
ON ST_CONTAINS(pickup.zip_code_geom, st_geogpoint(pickup_longitude, pickup_latitude))
JOIN (
SELECT zip_code, state_code, state_name, city, county, zip_code_geom, internal_point_lat, internal_point_lon
FROM `bigquery-public-data.geo_us_boundaries.zip_codes`
WHERE state_code='NY'
) AS dropoff
ON ST_CONTAINS(dropoff.zip_code_geom, st_geogpoint(dropoff_longitude, dropoff_latitude))
)
SELECT
DATETIME_TRUNC(pickup_datetime, hour) AS pickup_hour,
pickup_zip_code,
pickup_zip_code_lat,
pickup_zip_code_lon,
dropoff_zip_code,
dropoff_zip_code_lat,
dropoff_zip_code_lon,
COUNT(*) AS cnt
FROM base_data
WHERE pickup_datetime <= '2015-01-03'
GROUP BY 1,2,3,4,5,6,7
HAVING cnt >= 20
"""
agg_df = pd.read_gbq(query=agg_query, dialect='standard', project_id=project_id)
In [65]:
# 데이터 준비
agg_df.tail(7)
Out[65]:
In [66]:
import datetime
default_df = agg_df.loc[agg_df['pickup_hour'].dt.date == datetime.date(2015, 1, 1)]
In [67]:
# Layer 선택
arc_layer = pdk.Layer(
'ArcLayer',
default_df,
get_source_position='[pickup_zip_code_lon, pickup_zip_code_lat]',
get_target_position='[dropoff_zip_code_lon, dropoff_zip_code_lat]',
get_source_color='[255, 255, 120]',
get_target_color='[255, 0, 0]',
width_units='meters',
get_width="cnt",
pickable=True,
auto_highlight=True,
)
In [68]:
# ViewState 정의 어떤 시각에서 볼 것인지(좌표, Zoom Level, bearing 등)
nyc_center = [-73.9808, 40.7648]
view_state = pdk.ViewState(longitude=nyc_center[0], latitude=nyc_center[1], zoom=11)
In [69]:
# Deck 객체 생성하며 Layer, ViewState 연결 + Tooltip 추가
r = pdk.Deck(layers=[arc_layer], initial_view_state=view_state,
tooltip={
'html': '<b>count:</b> {cnt}',
'style': {
'color': 'white'
}
}
)
In [70]:
# 렌더링
r.show()

In [71]:
def visualize_demand(date=list(np.sort(agg_df['pickup_hour'].dt.date.unique())),
hour=widgets.IntSlider(min=0, max=23, step=1, value=0)):
filter_df = agg_df[(agg_df['pickup_hour'].dt.date == date) & (agg_df['pickup_hour'].dt.hour == hour)].to_dict(orient='records')
# arc_layer의 data를 바꿔치기
arc_layer.data = filter_df
r.update() # update가 핵심
In [72]:
r.show()
display(interact(visualize_demand))

실습¶
- 데이터 시각화쪽 코드 따라치기
- 치면서 인자도 바꿔보고, 어떻게 되는지 확인
- plot의 인자가 궁금하면 노트북에서 pd.DataFrame.plot? 을 입력하면 관련 method가 나옴
- 강의만 듣는게 아니라 따라쳐야 합니다!!!!
정리¶
- df.plot(), seaborn, cufflinks, matplotlib
- 결국 모든 것은 선택!
- 스프레드시트, Tableau 등 선호하는 도구가 있으면 좋음
- ipywidget을 활용해 Interactive 시각화 가능
- pydeck, kepler.gl 등을 활용하면 지리 데이터 시각화를 나름 편하게 할 수 있음
이번 주 숙제¶
- Pandas 활용 사례 따라치기 2회
- Visualization 따라치기 2회
- New York Taxi Data 추가적인 시각화
- ipywidget 사용해서 동적인 그래프 만들기
- pydeck으로 시각화 해보기
Colab 코드 제출해주세요(진지함)- 여러분 숙제를 해야 결국 실력 향상이 됩니다!
- 이거만 듣고 가는건 의미가..
다음 카일 스쿨¶
- 12월 27일은 제가 휴가라 Skip..
- 쉘 스크립트에 대해 알려드릴 예정
- 개인적으로 파이썬보다 더 좋다고 생각함
- 데이터 분석 직군은 딱히 익힐 일이 별로 없을 수 있는데, 꼭 참석하시길..
- 쉘 스크립트는 중요한 것 위주로 조금씩 진행해서 실습을 넣을 예정이에요
- 실습 : 카카오톡 대화 추출한 후, 그 방에서 제일 말 많이 하는 사람 Count하는 코드 짜기(터미널에서 1줄로 진행하기)