Apache Airflow - Workflow 관리 도구(1)
in Data on Engineering
- 오늘은 Workflow Management Tool인
Apache Airflow관련 포스팅을 하려고 합니다. - 이 글은 1.10.3 버전에서 작성되었습니다
- 최초 작성은 2018년 1월 4일이지만, 2020년 2월 9일에 글을 리뉴얼했습니다
- 슬라이드 형태의 자료를 원하시면 카일스쿨 6주차를 참고하시면 좋을 것 같습니다 :)
Apache Airflow를 사용하는 이유
- 데이터 엔지니어링에선 데이터 ETL(Extract, Transform, Load) 과정을 통해 데이터를 가공하며 적재함
- 머신러닝 분야에서도 모델 학습용 데이터 전처리, Train, Prediction시 사용 가능
- 위와 같은 경우 여러개의 Sequential한 로직(앞의 output이 뒤의 input이 되는)이 존재하는데 이런 로직들을 한번에 관리해야 함
- 관리할 로직이 적다면 CRON + 서버에 직접 접속해 디버깅 하는 방식으로 사용할 수 있지만, 점점 관리할 태스크들이 많아지면 헷갈리는 경우가 생김
- 이런 Workflow Management 도구는 airflow 외에도 하둡 에코시스템에 우지(oozie), luigi 같은 솔루션이 있음
Apache Airflow의 장점
- Apache Airflow는 Python 기반으로 만들어졌기 때문에, 데이터 분석을 하는 분들도 쉽게 코드를 작성할 수 있음
- Airflow 콘솔이 따로 존재해 Task 관리를 서버에서 들어가 관리하지 않아도 되고, 각 작업별 시간이 나오기 때문에 bottleneck을 찾을 때에도 유용함
- 또한 구글 클라우드 플랫폼(BigQuery, Dataflow)을 쉽게 사용할 수 있도록 제공되기 때문에 GCP를 사용하시면 반드시 사용할 것을 추천함
- Google Cloud Platform에는 Managed Airflow인 Google Cloud Composer가 있음
- 직접 환경을 구축할 여건이 되지 않는다면 이런 서비스를 사용하는 것을 추천 :)
Airflow Architecture

- Airflow Webserver - 웹 UI를 표현하고, workflow 상태 표시하고 실행, 재시작, 수동 조작, 로그 확인 등 가능
- Airflow Scheduler
- 작업 기준이 충족되는지 여부를 확인
- 종속 작업이 성공적으로 완료되었고, 예약 간격이 주어지면 실행할 수 있는 작업인지, 실행 조건이 충족되는지 등
- 위 충족 여부가 DB에 기록되면, task들이 worker에게 선택되서 작업을 실행함
1) Airflow 설치
Airflow는 pip로 설치 가능
pip install apache-airflow==1.10.3Extra Packages가 필요하다면 아래 명령어로 설치 가능
pip install apache-airflow[gcp]==1.10.3 # zsh이라면 # pip install 'apache-airflow[gcp]'==1.10.3- Airflow initdb
- airflow initdb는 처음 db를 생성하는 작업을 함
airflow initdb werkzeug 관련 오류가 발생한다면 아래 명령어로 라이브러리 설치
pip install werkzeug==0.15.4- Airflow 실행
- airflow는 webserver와 scheduler를 실행시킴
- webserver는 웹 서버를 담당하고, scheduler가 DAG들을 스케줄링(실행)함
airflow webserver -p 8080 # 터미널 새 창을 열어서 아래 커맨드 입력 airflow scheduler - 기본적으로 설치할 경우
~/airflow에 폴더가 생김- 폴더 내부에 있는 파일 간단 설명
airflow.cfg: Airflow 관련 설정airflow.db: sqlite 데이터베이스dags폴더(없다면mkdir dags로 생성!) : DAG 파일이 저장되는 장소
- 폴더 내부에 있는 파일 간단 설명
- 만약 1.10.0 이상 버전을 설치할 때, RuntimeError가 발생할 경우(RuntimeError: By default one of Airflow’s dependencies installs a GPL dependency)
환경 변수를 정의한 후 설치
export AIRFLOW_GPL_UNIDECODE=yes pip install apache-airflow
- webserver를 실행했으니
localhost:8080에서 UI를 확인할 수 있음
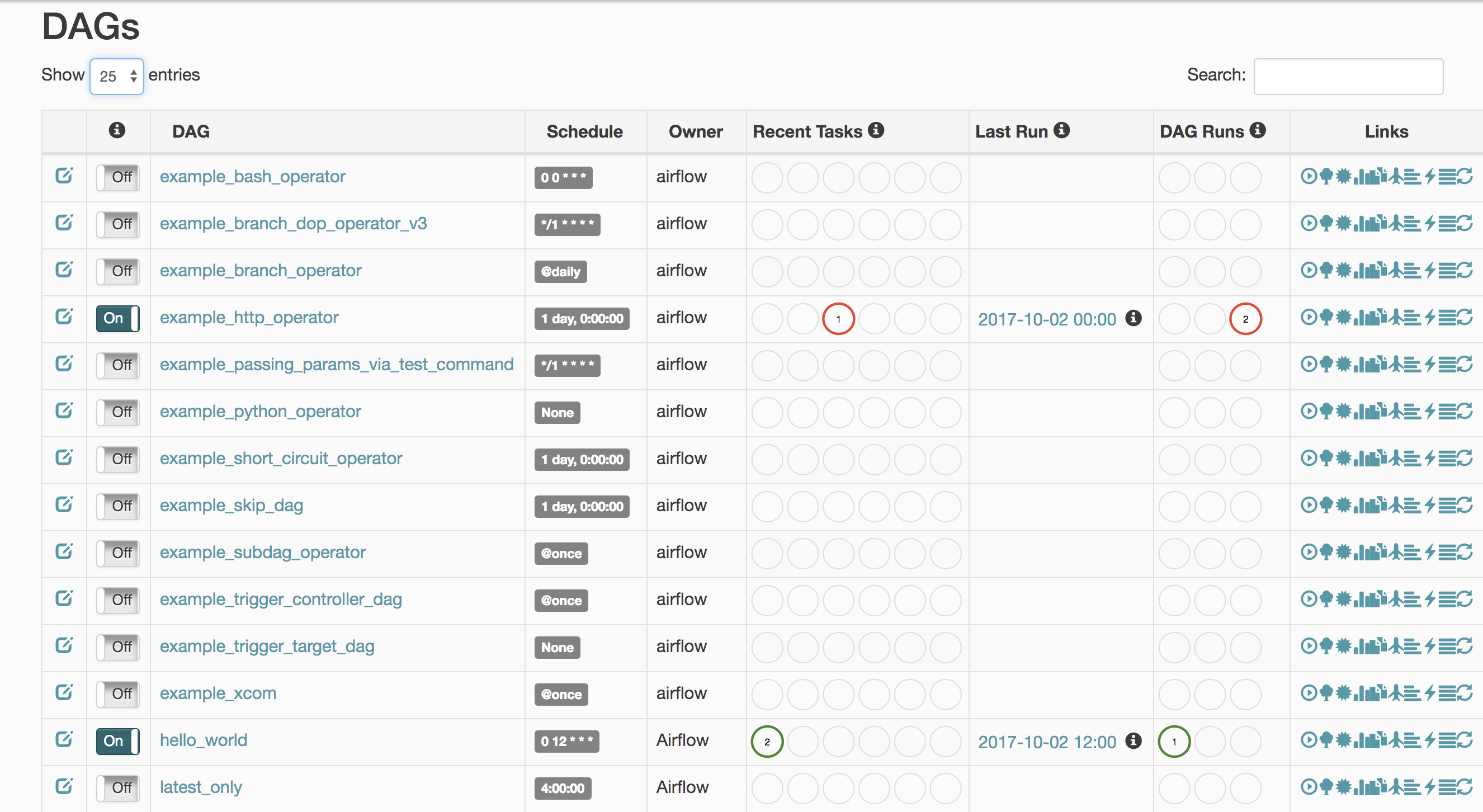
- DAG는 Directed Acyclic Graph의 약자로 Airflow에선 workflow라고 설명함
- Task의 집합체
- 메인 화면엔 정의되어 있는 DAG들을 확인할 수 있음
- 현재는 많은 example이 존재
- example을 보고싶지 않다면
airflow.cfg에서load_examples = False로 설정하면 됨
- Schedule은 예정된 스케쥴로 cron 스케쥴의 형태와 동일하게 사용
- Owner는 소유자를 뜻하는 것으로 생성한 유저를 뜻함
- Recent Tasks/DAG Runs에 최근 실행된 Task들이 나타나며, 실행 완료된 것은 초록색, 재시도는 노란색, 실패는 빨간색으로 표시됨
2) DAG 생성
- DAG 생성하는 흐름
- (1) default_args 정의
- 누가 만들었는지, start_date는 언제부턴지 등)
- (2) DAG 객체 생성
- dag id, schedule interval 정의
- (3) DAG 안에 Operator를 활용해 Task 생성
- (4) Task들을 연결함(
>>,<<활용)
- (1) default_args 정의
- Airflow는 $AIRFLOW_HOME(default는 ~/airflow)의 dags 폴더에 있는 dag file을 지속적으로 체크함
- Operator를 사용해 Task를 정의함
- Operator가 인스턴스화가 될 경우 Task라고 함
- Python Operator, Bash Operator, BigQuery Operator, Dataflow Operator 등
- Operator 관련 자료는 공식 문서 참고
- Operator는 unique한 task_id를 가져야 하고, 오퍼레이터별 다른 파라미터를 가지고 있음
- 아래 코드를 dags 폴더 아래에 test.py로 저장하고 웹서버에서 test DAG 옆에 있는 toggle 버튼을 ON으로 변경
- templated_command에서 % 앞뒤의 # 제거해주세요!
from airflow import models from airflow.operators.bash_operator import BashOperator from datetime import datetime, timedelta # start_date를 현재날자보다 과거로 설정하면, # backfill(과거 데이터를 채워넣는 액션)이 진행됨 default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date': datetime(2020, 2, 9), 'email': ['airflow@airflow.com'], 'email_on_failure': False, 'email_on_retry': False, 'retries': 1, 'retry_delay': timedelta(minutes=5)} # dag 객체 생성 with models.DAG( dag_id='test', description='First DAG', schedule_interval = '55 14 * * *', default_args=default_args) as dag: t1 = BashOperator( task_id='print_date', bash_command='date', dag=dag) # BashOperator를 사용 # task_id는 unique한 이름이어야 함 # bash_command는 bash에서 date를 입력한다는 뜻 t2 = BashOperator( task_id='sleep', bash_command='sleep 5', retries=3, dag=dag) templated_command=""" # #을 삭제해주세요 {#% for i in range(5) %#} echo "{#{ ds }#}" echo "{#{ macros.ds_add(ds, 7)}#}" echo "{#{ params.my_param }#}" {#% endfor %#} """ t3 = BashOperator( task_id='templated', bash_command=templated_command, params={'my_param': 'Parameter I passed in'}, dag=dag) # set_upstream은 t1 작업이 끝나야 t2가 진행된다는 뜻 t2.set_upstream(t1) # t1.set_downstream(t2)와 동일한 표현입니다 # t1 >> t2 와 동일 표현 t3.set_upstream(t1) - 다시 정리하면 DAG 객체 생성 -> Operator를 활용해 Task 작성 -> Task를 연결하는 방식
- {#{ ds }#}, {#{ macros }#}는 jinja template을 의미함
- 실제 사용시엔 #를 제외해주세요. 블로그 테마 때문에 추가함
- Macros reference, Jinja Template 참고하면 자세한 내용이 있음
- scheduler를 실행시켜 둔 상태라면 DAG들이 실행됨
3) Airflow 명령어
- DAG 파일을 추가하고, 웹서버에 보이기까지 시간이 좀 걸릴 수 있음
- DAG 파일들을 확인하고 싶은 경우
airflow의 dags 폴더 아래에 있는 dag들을 출력함
airflow list_dags
- 특정 DAG의 task를 출력하고 싶은 경우
test라는 DAG의 task 출력
airflow list_tasks testTree 형태로 출력
airflow list_tasks test --tree
- 특정 Task를 test하고 싶은 경우
date 날짜로 실행함
airflow test [DAG id] [Task id] [date]예시 : airflow test test print_date 2020-02-09
- Airflow scheduler 실행
DAG들이 실행됨
airflow scheduler
Airflow 관련 help 명령어
airflow -h
Airflow Webserver UI
- 특정 DAG을 클릭하고 Graph View를 클릭하면 아래와 같은 화면이 보임
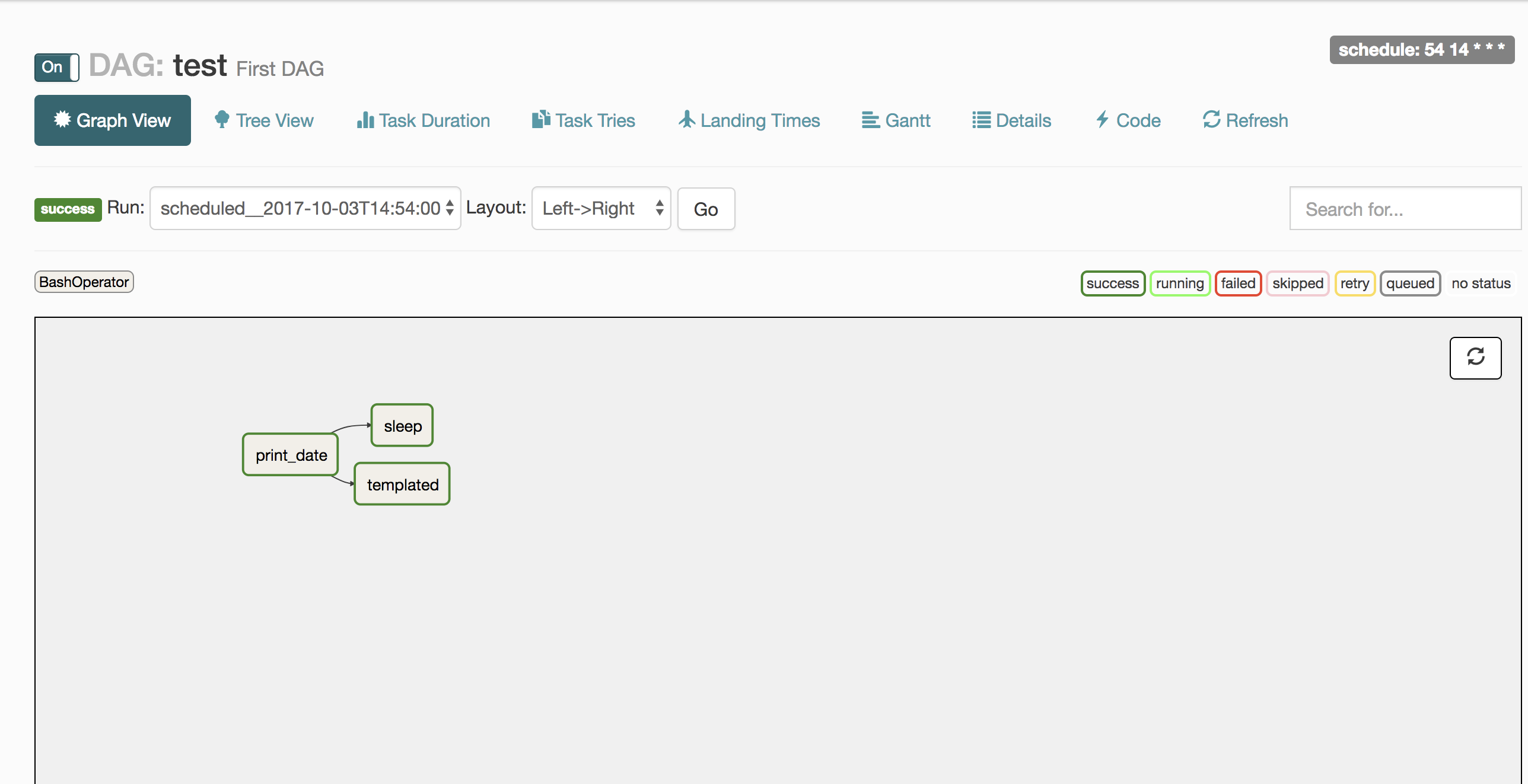
- print_date Task를 수행한 후, sleep Task와 templated Task를 실행함
- Tree View를 누르면 아래 화면이 나타남
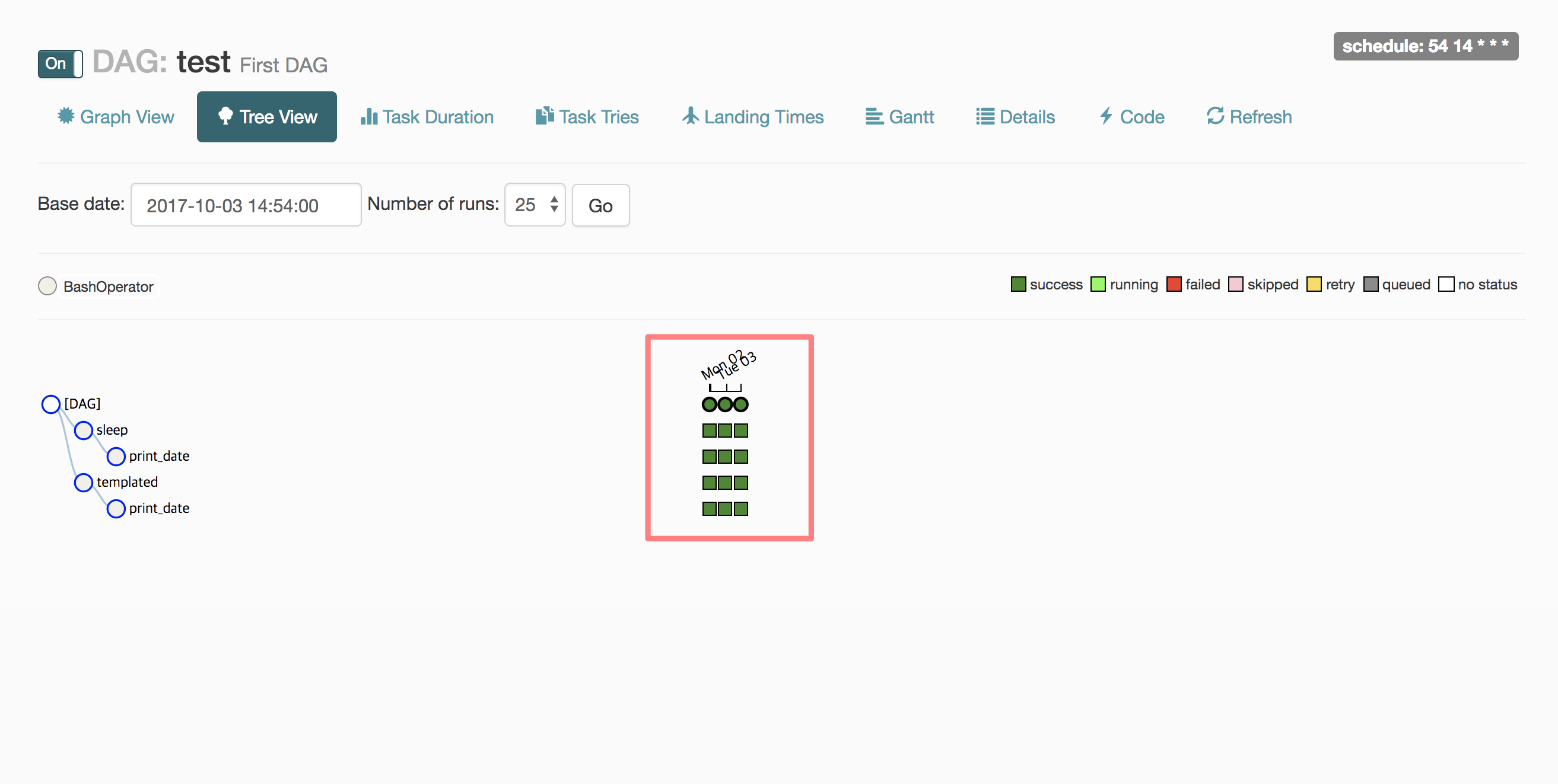
- 빨간색 네모 안에 있는 초록색 칸을 클릭하면 아래와 같은 설정이 나옴

- Task의 로그 확인(View Log), 실행(Run), 실행 상태 초기화(Clear) 등을 할 수 있음
- Task 재실행시 Run을 누르는 방법과 Clear를 누르는 방법이 있음
4) Connections 설정
- Airflow에서 MySQL, Google Cloud, Slack 등에 연결하고 싶은 경우 Admin - Connections에 설정을 저장해야 함
- Google Cloud BigQuery 설정하고 싶은 경우

- Project Id : 구글 클라우드 콘솔에 나오는 Project Id
- Keyfile Path : json keyfile의 경로를 입력
- Scopes : Scope 문서를 확인! https://www.googleapis.com/auth/cloud-platform 입력
Airflow 다양한 Tip
- pip로 설치하면 생기는 기본 설정
- sequential executor : 기본적으로 1개만 실행할 수 있음. 병렬 실행 불가능
- celery executor를 사용해 병렬로 실행할 수 있음
- 이건 RabbitMQ나 Redis가 필요함
- sqlite : 기본 meta store는 sqlite인데, 동시 접근이 불가능해서 병렬 불가능
- 병렬 실행하기 위해 mysql이나 postgresql을 사용해야 함
- sequential executor : 기본적으로 1개만 실행할 수 있음. 병렬 실행 불가능
- 위 설정을 서버에 매번 하는 일은 번거로운 일
Docker로 만들면 쉽게 가능- docker-airflow Github에 보면 이미 만들어진 Dockerfile이 있음
- docker-compose로 실행하는 방법도 있고, Airflow 버전이 올라가면 빠르게 업데이트하는 편
- Airflow의 DAG 폴더(default는 ~/airflow/dags)를 더 쉽게 사용하려면 해당 폴더를 workspace로 하는 jupyter notebook을 띄워도 좋음
- 데이터 분석가도 쉽게 DAG 파일 생성 가능
- Error: Already running on PID XXXX 에러 발생시
- Airflow webserver 실행시 ~/airflow/airflow-webserver.pid에 process id를 저장함
- 쉘에서 빠져나왔지만 종료되지 않는 경우가 있음
아래 명령어로 pid를 죽이면 됨(다른 포트를 사용할 경우 8080쪽 수정)
kill -9 $(lsof -t -i:8080)
- Task간 데이터를 주고 받아야 할 경우
- xcom 사용
- Admin - xcom에 들어가면 값이 보임
xcom에 데이터 저장(xcom_push)
task_instance = kwargs['task_instance'] task_instance.xcom_push(key='the_key', value=my_str)다른 task에서 데이터 불러오기(xcom_pull)
task_instance.xcom_pull(task_ids='my_task', key='the_key')- 참고로 PythonOperator에서 사용하는 python_callable 함수에서 return하는 값은 xcom에 자동으로 push됨
- DAG에서 다른 DAG에 종속성이 필요한 경우
- ExternalTaskSensor 사용
- 1개의 DAG에서 하면 좋지만, 여러 사람이 만든 DAG이 있고 그 중 하나를 사용해야 할 경우도 있음
- 특정 DAG을 Trigger하고 싶은 경우
- 특정 Task의 성공/실패에 따라 다른 Task를 실행시키고 싶은 경우
- Airflow Trigger Rule 사용
- 예를 들어 앞의 두 작업중 하나만 실패한 경우
- Document 참고
- Jinja Template이 작동하지 않는 경우
- 우선 provide_context=True 조건을 주었는지 확인
- Jinja Template이 있는 함수의 파라미터가 어떤 것인지 확인
Operator마다 Jinja Template을 해주는 template_fields가 있는데, 기존 정의가 아닌 파라미터에서 사용하고 싶은 경우 새롭게 정의
class MyPythonOperator(PythonOperator): template_fields = ('templates_dict','op_args')
- Airflow 변수를 저장하고 싶은 경우
- Variable 사용
- Admin - Variables에서 볼 수 있음
- json 파일로 변수 저장해서 사용하는 방식을 자주 사용함
from airflow.models import Variable config=Variable.get(f"{HOME}/config.json", deserialize_json=True) environment=config["environment"] project_id=config["project_id"] - Task를 그룹화하고 싶은 경우
- dummy_operator 사용
- workflow 목적으로 사용하는 경우도 있음. 일부 작업을 건너뛰고 싶은 경우, 빈 작업 경로를 가질 수 없어서 dummy_operator를 사용하기도 함
1개의 Task이 완료된 후에 2개의 Task를 병렬로 실행하기
task1 >> [task2_1, task_2_2]- 앞선 Task의 결과에 따라 True인 경우엔 A Task, False인 경우엔 B Task를 실행해야 하는 경우
- BranchPythonOperator 사용
- python_callable에 if문을 넣어 그 다음 task_id를 정의할 수 있음
- 단순하게 앞선 task가 성공, 1개만 실패 등이라면 trigger_rule만 정의해도 됨
- Airflow에서 Jupyter Notebook의 특정 값만 바꾸며 실행하고 싶은 경우
- Papermill 사용
- 참고 문서
- UTC 시간대를 항상 생각하는 습관 갖기
- execution_date이 너무 헷갈림
- 2017년에 Airflow 처음 사용할 때 매우 헷갈렸던 개념
- 박호균님의 블로그 참고
- 추후 다른 글로 정리할 예정
- Task가 실패했을 경우 슬랙 메세지 전송하기
- Integrating Slack Alerts in Airflow 참고하면 잘 나와있음
- Hook이란?
- Hook은 외부 플랫폼, 데이터베이스(예: Hive, S3, MySQL, Postgres, Google Cloud Platfom 등)에 접근할 수 있도록 만든 인터페이스
- 대부분 Operator가 실행되기 전에 Hook을 통해 통신함
- 공식 문서 참고
- 머신러닝에서 사용한 예시는 Github 참고
- airflow Github에 많은 예제 파일이 있음
- Context Variable이나 Jinja Template의 ds를 사용해 Airflow에서 날짜를 컨트롤 하는 경우, Backfill을 사용할 수 있음
- 과거값 기준으로 재실행
- 단, 쿼리에 CURRENT_DATE() 등을 쓰면 Airflow에서 날짜를 컨트롤하지 않고 쿼리에서 날짜 컨트롤하는 경우라 backfill해도 CURRENT_DATE()이 있어서 현재 날짜 기준으로 될 것임
airflow backfill -s 2020-01-05 -e 2020-01-10 dag_id- backfill은 기본적으로 실행되지 않은 Task들만 실행함. DAG을 아예 다시 실행하고 싶다면
--reset_dagruns를 같이 인자로 줘야 함
airflow backfill -s 2020-01-05 -e 2020-01-10 --reset_dagruns dag_id- 실패한 Task만 재실행하고 싶다면
--rerun_failed_task를 사용함
airflow backfill -s 2020-01-05 -e 2020-01-10 --reset_failed_task dag_id airflow backfill이 아닌 강제로 trigger를 하고 싶다면 다음 명령어 사용
airflow trigger_dag dag_id -e 2020-01-01- 재시도시 Exponential하게 실행되길 원하면
retry_exponential_backoff참고
airflow 1.10.8, 1.10.9 버전부터 tag 기능이 생김. DAG을 더 잘 관리할 수 있음
dag = DAG( dag_id='example_dag_tag', schedule_interval='0 0 * * *', tags=['example'] )- Airflow Summit 2020의 영상도 보시면 좋을 것 같습니다!
추천 자료
- Airflow Summit 2020
- Airflow Tutorial : Video 자료 존재
- Lyft의 Airflow 활용 사례
- Awesome Apache Airflow : Airflow 관련 링크 모음
- ETL best practices with Airflow : 1.8 버전이지만 내용들이 좋음
- 제 Github : Airflow example 저장하는 중
- 제 다른 Github : ML에서 활용한 Airflow
- Airflow: Lesser Known Tips, Tricks, and Best Practises
- Airflow and XCOM: Inter Task Communication Use Cases
- Docker Airflow Github
- Airflow about subDAGs, branching and xcom
- What’s coming in Apache Airflow 2.0
- 카카오페이지의 Airflow를 활용하여 아름다운 데이터 파이프라인 구성하기
카일스쿨 유튜브 채널을 만들었습니다. 데이터 분석, 커리어에 대한 내용을 공유드릴 예정입니다.
PM을 위한 데이터 리터러시 강의를 만들었습니다. 문제 정의, 지표, 실험 설계, 문화 만들기, 로그 설계, 회고 등을 담은 강의입니다
이 글이 도움이 되셨거나 의견이 있으시면 댓글 남겨주셔요.
