시계열 예측을 위한 Facebook Prophet 사용하기
in Data on Time Series
- 페이스북이 만든 시계열 예측 라이브러리 Prophet 사용법에 대해 작성한 글입니다
- Prophet은 Python, R로 사용할 수 있는데, 본 글에선 Python로 활용하는 방법에 대해서만 다룹니다
Prophet
- 페이스북이 만든 시계열 예측 라이브러리
- 통계적 지식이 없어도 직관적 파라미터를 통해 모형을 조정할 수 있음
- 일반적인 경우 기본값만 사용해도 높은 성능을 보여줌
- 내부가 어떻게 동작하는지 고민할 필요가 없음
- (개인 의견) 사실 이게 개인으로선 아쉬운 점.. 내부 알고리즘을 공개하진 않고 Linear Model이다! 정도만 알려줌
- Python, R로 사용 가능
- 현재 Version 0.4(2018.12.18)로 아직 1점대 미만이라 언제든 API가 변경되도 이상하지 않음
- 관련 자료
- 공식 홈페이지
- Prophet 논문
- 영어라 읽기 힘들다면 모든이들을 위한 FACEBOOK PROPHET PAPER 쉬운 요약정리 참고하면 좋을 것 같음!
설치
pip3 install fbprophet
Prophet 구성 요소
- Growth, Seasonality, Holidays
- \[y(t)=g(t)+s(t)+h(t)+error\]
- ARIMA 같은 시계열 모델은 시간에 종속적인 구조를 가지는 반면 Prophet은 종속적이지 않고 Curve Fitting으로 문제를 해결
- 학습 속도가 빠르고, 빈 구간을 interpolate하지 않아도 됨
- 직관적으로 이해할 수 있는 파라미터를 통해 모형을 쉽게 조정 가능
Growth
- Linear Growth(+Change Point)
- Change Point는 자동으로 탐지
- 예측할 때는 특정 지점이 change point인지 여부를 확률적으로 결정
- Non-Linear Growth(Logistic Growth)
- 자연적 상한성이 존재하는 경우, Capacity가 있음
- Capacity는 시간에 따라 변할 수 있음
Seasonality
- 사용자들의 행동 양식으로 주기적으로 나타나는 패턴
- 방학, 휴가, 온도, 주말 등등
- 푸리에 급수(Fourier Series)를 이용해 패턴의 근사치를 찾음
- 공돌이의 수학정리노트, CT Fourier Series
- 나무위키 푸리에 해석
Holidays
- 주기성을 가지진 않지만 전체 추이에 큰 영향을 주는 이벤트가 존재
- 이벤트의 효과는 독립적이라 가정
- 이벤트 앞뒤로 window 범위를 지정해 해당 이벤트가 미치는 영향의 범위를 설정할 수 있음
Model Fitting
- Stan을 통해 모델을 학습
- probabilistic programming language for statistical inference
- 2가지 방식
- MAP (Maximuam A Posteriori) : Default, 속도가 빠름
- MCMC (Markov Chain Monte Carlo) : 모형의 변동성을 더 자세히 살펴볼 수 있음
- Analyst in the loop Modeling
- 통계적 지식이 없어도 직관적 파라미터를 통해 모형을 조정할 수 있음
- 일반적인 경우 기본값만 사용해도 높은 성능을 가능
- 내부가 어떻게 동작하는지 고민할 필요가 없음
- 요소
- Capacities : 시계열 데이터 전체의 최대값
- Change Points : 추세가 변화하는 시점
- Holidays & Seasonality : 추세에 영향을 미치는 시기적 요인
- Smoothing : 각각의 요소들이 전체 추이에 미치는 영향의 정도
Prophet 사용법
- 1) 데이터를 Prophet에 맞도록 가공
- 필요한 컬럼은 ds, y 2개!(컬럼 이름을 맞춰야함)
from fbprophet import Prophet import pandas as pd df = pd.read_csv("./data/example_wp_log_peyton_manning.csv")- 예측값의 상한과 하한을 제어해야 하면
cap,floor컬럼에 값 지정
df['cap'] = 6 df['floor'] = 1.5 - 2) Prophet 객체 생성하고 Fit
- Prophet 객체는 1번만 Fit 할 수 있음. 만약 여러번 Fit 하고 싶으면 새로운 객체를 생성해야 함
m = Prophet() # Default growth='linear' m.fit(df)- 상한과 하한을 설정할 경우엔 Prophet 객체를 생성할 때 growth=’logistic’ 추가
m = Prophet(growth='logistic') m.fit(df) 3) 미래 Dataframe 생성
future = m.make_future_dataframe(periods=365) future.tail()- 1)에서 예측값의 상한이나 하한을 설정했으면 동일하게 지정
future['cap'] = 6 future['floor'] = 1.54) 예측
forecast = m.predict(future) forecast.tail()- 5) forecast 결과 확인
- yhat_lower, yhat_upper 같이 범위로 제공
forecast.tail() forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail(60) - 6) 시각화
- forecast 시각화
fig1 = m.plot(forecast)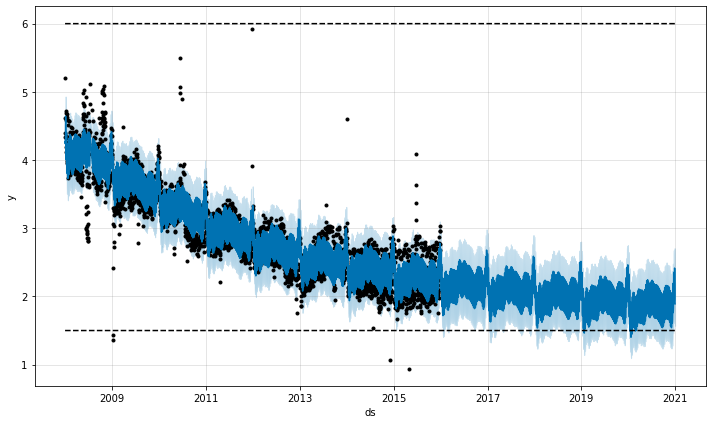
- 점선들이 하한선과 상한선
- forecast component 시각화(Trend, Weakly, Yearly)
fig2 = m.plot_components(forecast)
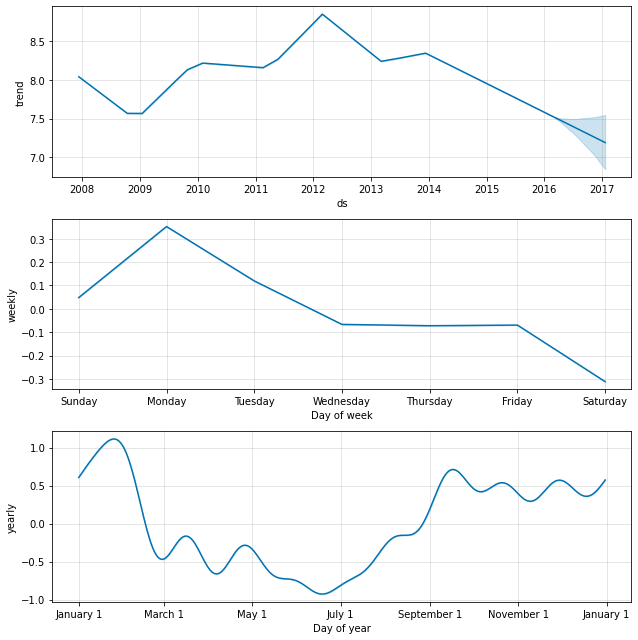
Trend Change Points
- Prophet에선 기본적으로 트렌드가 변경되는 지점을 자동으로 감지해 트렌드를 예측함
- 감지하는 것을 사용자가 조절할 수 있음
- Prophet 객체를 생성할 때
changepoint_range,changepoint_prior_scale,changepoints을 조절- 1) changepoint_range
- 기본적으로 Prophet은 시계열 데이터의 80% 크기에서 잠재적으로 ChangePoint를 지정
- 90%만큼 ChangePoint로 지정하고 싶다면 아래와 같이 설정
m = Prophet(changepoint_range=0.9) - 2) changepoint_prior_scale
- Change Point의 유연성을 조정하는 방법
- 오버피팅이 심하면 너무 유연한 그래프가 나와서 모든 값에 근접하고, 언더피팅일 경우 유연성이 부족
- 기본 값은 0.05
- 이 값을 늘리면 그래프가 유연해지고(=언더피팅 해결), 이 값을 줄이면 유연성이 감소(=오버피팅 해결)
m = Prophet(changepoint_prior_scale=0.05) - 3) changepoints(list)
- 잠재적으로 change point일 수 있는 날짜들
- 명시하지 않으면 잠재적인 changepoint가 자동으로 설정됨
m = Prophet(changepoints=['2019-02-04'. '2019-02-05'])
- 1) changepoint_range
시각화
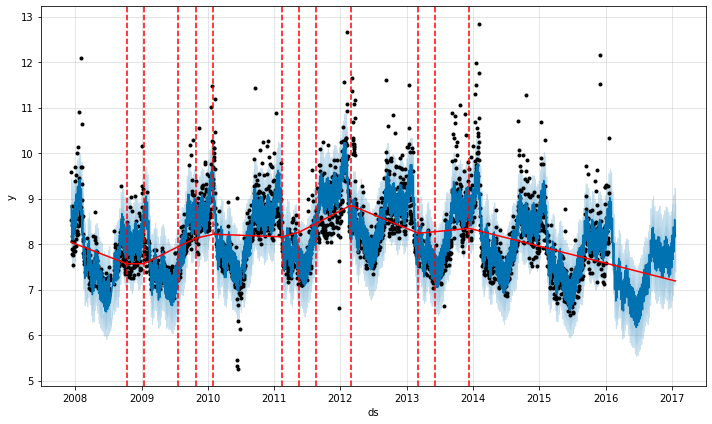
from fbprophet.plot import add_changepoints_to_plot fig = m.plot(forecast) a = add.changepoints_to_plot(fig.gca(), m, forecast)- 빨간 점선 : ChangePoint
- 빨간 실선 : Trend
Seasonality, Holiday Effects, And Regressors
- Modeling Holidays and Special Events
- 휴일이나 모델에 반영하고 싶은 이벤트가 있으면 Dataframe을 생성해 반영할 수 있음
- 이벤트는 과거 데이터와 미래 데이터가 모두 포함되어 있어야 함
- 주변 날짜를 포함시키기 위해
lower_window,upper_window를 사용해 업데이트의 영향을 조절 가능 - 예제는 Play Off 경기일과 SUperbowl 경기날을 Holiday로 설정
playoffs = pd.DataFrame({ 'holiday': 'playoff', 'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16', '2010-01-24', '2010-02-07', '2011-01-08', '2013-01-12', '2014-01-12', '2014-01-19', '2014-02-02', '2015-01-11', '2016-01-17', '2016-01-24', '2016-02-07']), 'lower_window': 0, 'upper_window': 1, }) superbowls = pd.DataFrame({ 'holiday': 'superbowl', 'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']), 'lower_window': 0, 'upper_window': 1, }) holidays = pd.concat((playoffs, superbowls))- 사용하는 방법은 간단, Prophet 객체를 생성할 때 holidays 인자로 넘기면 됨
m = Prophet(holidays=holidays) forecast = m.fit(df).predict(future)- holiday effect를 아래 코드로 확인할 수 있음
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][ ['ds', 'playoff', 'superbowl']][-10:]- plot_component로 시각화할 경우 holidays의 영향도 볼 수 있음
fig = m.plot_components(forecast)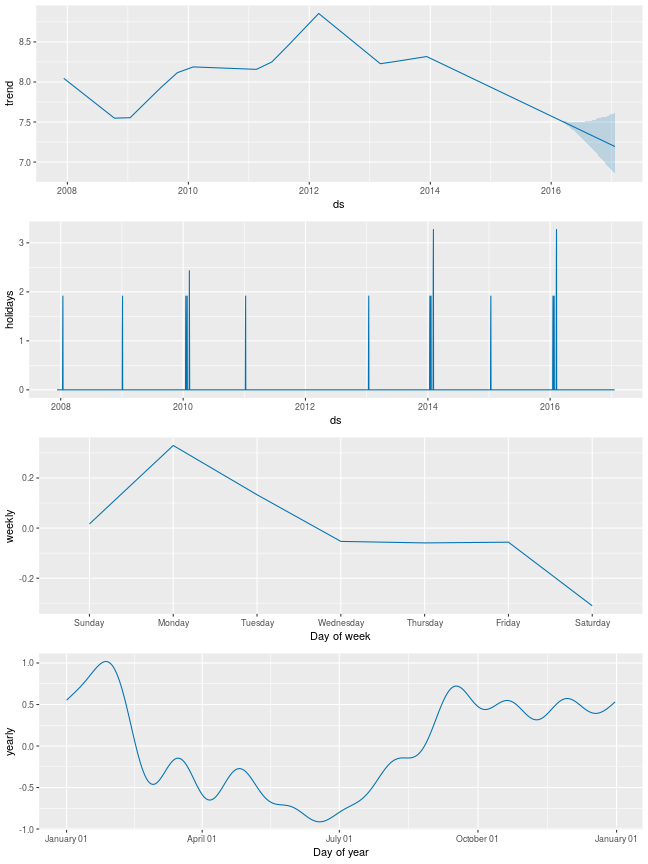
- 만약 holidays에 오버피팅된 것 같으면
holidays_prior_scale을 조정해 smooth하게 변경 가능(기본값은 10)
m = Prophet(holidays=holidays, holidays_prior_scale=0.05).fit(df) forecast = m.predict(future) forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][ ['ds', 'playoff', 'superbowl']][-10:] - Built-in Country Holidays
- Prophet 객체를 생성한 후, m.add_country_holidays(country_name=’US’) 이렇게 작성하면 국가의 휴일을 사용할 수 있음
- 그러나 한국은 없음
- Github 참고해서 만들어도 될 듯, 혹은 커스텀 이벤트를 생성
- Fourier Order for Seasonalities
- Seasonalities를 부분 푸리에의 합을 사용해 추정
- 이 부분은 논문에 자세히 나오고, 위키피디아도 참고하면 좋음
- 푸리에 급수는 주기함수를 삼각함수의 급수로 나타낸 것
yearly_seasonality파라미터의 default는 10- 만약 시즈널리티가 자주 발생한다고 생각하면 이 값을 20으로 수정하면 됨. 단, 오버피팅 조심!
from fbprophet.plot import plot_yearly m = Prophet(yearly_seasonality=10).fit(df) a = plot_yearly(m) - Specifying Custom Seasonalities
- 커스텀 시즈널리티를 생성할 수 있음
- 기본적으로 weekly, yearly 특성 제공
- m.add_seasonality로 추가하며 인자는 name, period, fourier_order가 있음
m = Prophet(weekly_seasonality=False) m.add_seasonality(name='monthly', period=30.5, fourier_order=5) forecast = m.fit(df).predict(future) fig = m.plot_components(forecast)
prior_scale을 조절해 강도를 조절할 수 있음
- Additional regressors
add_regressor메소드를 사용해 모델의 linear 부분에 추가할 수 있음예제에선 NFL 시즌의 일요일에 추가 효과를 더함
def nfl_sunday(ds): date = pd.to_datetime(ds) if date.weekday() == 6 and (date.month > 8 or date.month < 2): return 1 else: return 0 df['nfl_sunday'] = df['ds'].apply(nfl_sunday) m = Prophet() m.add_regressor('nfl_sunday') m.fit(df) future['nfl_sunday'] = future['ds'].apply(nfl_sunday) forecast = m.predict(future) fig = m.plot_components(forecast)

Multiplicative Seasonality
- 단순한 seasonality가 아닌 점점 증가하는 seasonlity를 다룰 때 사용하면 좋은 기능
- 데이터가 엄청 많을 경우 유용할 듯
- 사용하는 방법은 매우 단순. seasonality_mode의 인자로 multiplicative 지정
m = Prophet(seasonality_mode='multiplicative')
Uncertainty Intervals
- 불확실성의 범위가 나타나는 원인
- 1) Trend의 불확실성
- 2) Seasonality 추정의 불확실설
- 3) 추가 관찰되는 잡음
- Uncertainty in the trend
- 예측을 하면 yhat_lower, yhat_upper가 나타나는데 이 범위도 사용자가 조절할 수 있음
interval_width의 기본 값은 80%- changepoint_prior_scale을 조절하면 예측 불확실성이 증가함
forecast = Prophet(interval_width=0.95).fit(df).predict(future) - Uncertainty in seasonality
- 시즈널리티의 불확실성을 알기 위해 베이지안 샘플링을 사용해야 함
- mcmc.samples 파라미터를 사용. 이 값을 사용하면 최초 n일에 대해 적용한다는 뜻
m = Prophet(mcmc_samples=300) forecast = m.fit(df).predict(future) fig = m.plot_components(forecast)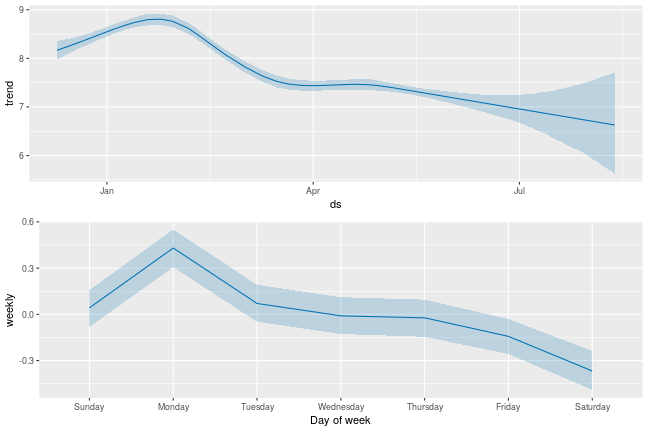
- 이제 불확실성의 범위가 보임
Outliers
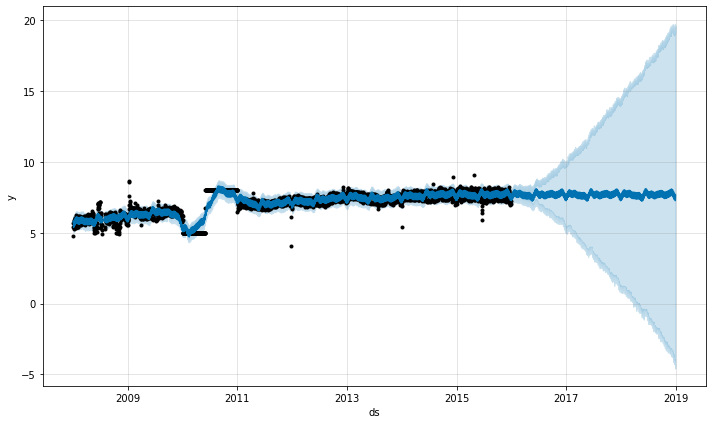
- 위와 같은 예측 그래프를 보면, 2016년부터 Uncertainty Intervals이 너무 큼
- 너무 튀는 값이 존재해서 예측할 때 영향이 미침
- 이런 값들은 제외하고 예측해야 함
- NA, None로 설정
- 또는 상한선, 하한선 설정
df.loc[(df['ds'] > '2010-01-01') & (df['ds'] < '2011-01-01'), 'y'] = None model = Prophet().fit(df) fig = model.plot(model.predict(future)) - 이런 값들은 제외하고 예측해야 함
Sub-daily Data
- 여태까지 사례는 모두 Daily 데이터였는데, 더 짧은 단위도 예측할 수 있음
- Timestamp로 YYYY-MM-DD HH:MM:SS 형태로 저장
- 사실 데이터 형태만 다른거고 여태와 동일함
- Data with regular gaps
- 정기적인 gap이 있는 데이터도 예측할 수 있음
- 매달 1일의 데이터만 있어도 월별로 예측 가능(부정확성이 더 늘겠지만!)
기타
- 공식 문서는 Tutorial정도로만 충실하고, 추가되는 API에 대한 설명이 없음(=소스코드 까서 직접..)
- fbprophet의 diagnostics.py엔 아래 기능이 구현되어 있음
- cross_validation
- performance_metrics
- mse, rmse, mae, mape, coverage
- 깔끔하고 간단하게 짜여있으니 참고해도 좋을듯
- plot.py엔 아래 기능이 구현되어 있음
- plot_yearly, plot_weekly, plot_seasonality, plot_cross_validation_metric 등
- fbprophet의 diagnostics.py엔 아래 기능이 구현되어 있음
마무리
- 시계열 분석에 대해 잘 알지는 못하지만, 예측을 해야될 경우 사용하면 좋은 라이브러리입니다
- 다른 방식의 접근(예를 들면 카테고리컬로 regression)과 동시에 진행하고 Stacking해도 좋을 것 같아요!
- 구현된 코드는 시계열 예측할 때 자주 사용될 코드들이 있어서 구현 코드를 파악해도 좋을 것 같아요!
참고 코드
Reference
- 공식 홈페이지
- 이민호님의 Slideshare
카일스쿨 유튜브 채널을 만들었습니다. 데이터 분석, 커리어에 대한 내용을 공유드릴 예정입니다.
PM을 위한 데이터 리터러시 강의를 만들었습니다. 문제 정의, 지표, 실험 설계, 문화 만들기, 로그 설계, 회고 등을 담은 강의입니다
이 글이 도움이 되셨거나 의견이 있으시면 댓글 남겨주셔요.
