BigQuery UNNEST, ARRAY, STRUCT 사용 방법
- BigQuery Unnest, Array, Struct 사용 방법에 대해 작성한 글입니다
- 목차
들어가며
- BigQuery는 SQL 문법을 사용하고 있기 때문에, 많은 사람들이 처음에 쉽게 접할 수 있음
- 그러나 자주보기 힘든 ARRAY, STRUCT, UNNEST를 만나면 많은 사람들이 어려워함
- 특히 Google Analytics 데이터나 Firebase 데이터 작업시 Cannot access field name on a value with type ARRAY 이런 Error를 접함
- 자료형들에 대한 설명과 이런 데이터를 쿼리할 때 어떻게 사용해야 하는지에 대해 정리하려고 함
- 참고로, BigQuery는 비정규화되었을 때 성능이 가장 뛰어남
- 비정규화를 위해 중첩(Nested) 및 반복(Repeated) 열을 사용함
- 중첩된 레코드를 사용할 때 장점
- 빅쿼리 퍼포먼스 개선
- 데이터 저장 용량의 효율
- 스키마가 바뀌어도 유연하게 대응 가능
- 이 내용은 BigQuery Document에 나옴
BigQuery ARRAY
- 배열 함수 Document
- BigQuery는 데이터 유형이 동일한 값으로 구성된 목록을 ARRAY(배열)라 부름
- 파이썬의 List와 유사함(완전히 동일하진 않음)
- 하나의 행에 데이터 타입이 동일한 여러 값이 저장됨
- 빅쿼리 UI에서 배열을 보여줄 때 세로로 나열됨
SELECT [1,2,3] AS array_sample, 1 AS int_value UNION ALL SELECT [3,5,7] AS array_sample, 2 AS int_value- 쿼리 결과

- 행을 보면 1과 2만 있고, 1 안에 array_sample에 1, 2, 3이 세로로 출력됨. 반면에 단순 숫자값을 나열한 int_value는 1개만 보임
- 행 하나에 딸려있는 경우 ARRAY!
- array_sample이 ARRAY(int_value는 INT64)
- ARRAY 생성 방법
1) 대괄호(
[,]) 사용SELECT [1, 2, 3] AS array_sample- 2) ARRAY<> 사용
- ARRAY<타입>을 작성하고 괄호 사용
SELECT ARRAY<INT64>[1,2,3] AS int_array - 3) GENERATE 함수 사용
- GENERATE_ARRAY, GENERATE_DATE_ARRAY, GENERATE_TIMESTAMP_ARRAY 등 사용
- GENERATE_ARRAY(시작, 종료, 간격) : python에서 range(start, end, step)과 동일함
SELECT GENERATE_ARRAY(1, 10, 2) AS generate_array_data
- GENERATE_DATE_ARRAY도 GENERATE_ARRAY와 동일
SELECT GENERATE_DATE_ARRAY('2020-01-01', '2020-02-01', INTERVAL 1 WEEK) AS generate_date_array_data - 4) ARRAY_AGG 사용
- ARRAY_AGG, ARRAY_CONCAT_AGG 등 사용
- Table에 저장된 데이터를 SELECT하고 ARRAY로 묶고싶은 경우 사용
WITH programming_languages AS (SELECT "python" AS programming_language UNION ALL SELECT "go" AS programming_language UNION ALL SELECT "scala" AS programming_language) SELECT ARRAY_AGG(programming_language) AS programming_languages_array FROM programming_languages
- 여기서 SELECT [“python”, “go”, “scala”] as programming_language로 가능한거 아니냐고 생각할 수 있는데, 데이터를 만드는 과정이라면 둘 다 가능하지만, Table에 저장된 데이터를 SELECT해서 집계할 땐 이렇게 해야함
- SELECT ARRAY[programming_language] AS programming_languages_array 이런 쿼리를 직접 돌려보면 배열이 아닌 행에 하나의 값만 저장되는 것을 볼 수 있음. ARRAY_AGG을 사용!
- 만약 배열 안에 NULL이 하나라도 있는 경우, ARRAY_AGG의 결과는 NULL이 나온다
- 이 경우 IGNORE NULLS을 추가하면 널을 제외하고 연산함
SELECT ARRAY_AGG(x IGNORE NULLS) FROM UNNEST([1, NULL, 2, 4, 6]) x- ARRAY_AGG의 옵션 절에 궁금하면 ARRAY_AGG를 참고하면 된다(DISTINCT, IGNORE NULLS, ORDER BY 등을 사용할 수 있음)
- 배열 내 접근
- 배열의 N번째 값을 가져오고 싶은 경우 OFFSET, ORDINAL을 사용할 수 있음
- OFFSET : 0부터 시작
- ORDINAL : 1부터 시작
- 존재하지 않는 N을 지정하면 에러가 발생하는데, 이럴 경우 SAFE_를 앞에 붙여주면(SAFE_OFFSET, SAFE_ORDINAL) 에러가 발생하지 않고 NULL이 return됨
WITH programming_languages AS (SELECT "python" AS programming_language UNION ALL SELECT "go" AS programming_language UNION ALL SELECT "scala" AS programming_language) SELECT ARRAY_AGG(programming_language)[OFFSET(0)] AS programming_languages_array, ARRAY_AGG(programming_language)[ORDINAL(1)] AS programming_languages_array2 FROM programming_languages - 배열을 역순으로 반환하고 싶은 경우
- ARRAY_REVERSE 함수 사용
WITH programming_languages AS (SELECT "python" AS programming_language UNION ALL SELECT "go" AS programming_language UNION ALL SELECT "scala" AS programming_language) SELECT ARRAY_REVERSE(ARRAY_AGG(programming_language)) AS programming_languages_array_reverse FROM programming_languages - 배열의 길이(배열에 있는 요소들의 개수)가 궁금한 경우
- ARRAY_LENGTH 사용
WITH example_data AS( SELECT 'kyle' AS name, ['Python', 'SQL', 'R', 'Julia', 'Go'] AS preferred_language, 31 AS age UNION ALL SELECT 'max' AS name, ['Python', 'SQL', 'Scala', 'Java', 'Kotlin'] AS preferred_language, 29 AS age UNION ALL SELECT 'yun' AS name, ['Python', 'SQL'] AS preferred_language, 28 AS age ) SELECT *, ARRAY_LENGTH(preferred_language) AS preferred_language_len FROM example_data



BigQuery STRUCT
- 데이터 유형 Document
- 구조체로, BigQuery UI에서 RECORD로 표현됨
- 각각 유형(필수)과 필드 이름(선택사항)이 있는 정렬된 필드의 컨테이너
- C의 Struct
- Python 3.7에 나온 Data Class와 유사. 참고 Stackoverflow
- 처음엔 Python의 Dict과 유사한 느낌(절대 같지 않음!!!)이라 생각하면 편함
- Python에서 Dict in List, List in Dict, List in List 처럼 BigQuery의 ARRAY와 STRUCT도 Array in Struct, Struct in Array, Struct in Struct 등이 가능함
- 따라서 ARRAY를 접하다보면 STRUCT도 알아야 할 경우가 생김(그러나 ARRAY가 더 많이 사용됨)
- Firebase에서 저장된 데이터를 볼 때 특히!
- STRUCT 생성 방법
- 1) 소괄호(
(,)) 사용SELECT (1,2,3) AS struct_test 
- 2) STRUCT<> 사용
- <> 안에 타입을 지정해서 사용
SELECT STRUCT<INT64, INT64, STRING>(1, 2, 'HI') AS struct_test 
- 타입 앞에 이름을 지정할 수 있음
SELECT STRUCT<hi INT64, hello INT64, awesome STRING>(1, 2, 'HI') AS struct_test
- 또는 타입을 지정하지 않고, AS로 이름을 지정할 수 있음
SELECT STRUCT(1 as hi, 2 as hello, 'HI' as awesome) AS struct_test - <> 안에 타입을 지정해서 사용
- 3)
STRUCT<x STRUCT<y INT64, z STRING>>- 이런 표현을 종종 볼 수 있는데, 해석하면 바깥 STRUCT 안에 x라는 이름을 가진 STRUCT가 있고, 그 STRUCT엔 INT64 타입인 값이 1개, STRING 1개가 저장된 경우
SELECT STRUCT<struct_example STRUCT<y INT64, z STRING>>((2, 'HI')) AS struct_test- 위 예시에선 바깥 STRUCT 이름은 AS struct_test로 정의함

- 4) ARRAY 안에 여러 STRUCT를 사용하고 싶은 경우
- ARRAY(SELECT AS STRUCT) 이런 형태로 사용
SELECT ARRAY( SELECT AS STRUCT 1 as hi, 2, 3 UNION ALL SELECT AS STRUCT 4 as hi, 5, 6 ) AS new_array
- 1) 소괄호(

BigQuery UNNEST
- UNNEST Document
- 예시를 위해 사람들이 선호하는 프로그래밍 언어와 나이가 저장된 데이터가 있다고 가정
- 배열에 통째로 접근하고 싶은 경우엔 평소처럼 컬럼을 지정
- preferred_language
WITH example_data AS( SELECT 'kyle' AS name, ['Python', 'SQL', 'R', 'Julia', 'Go'] AS preferred_language, 31 AS age UNION ALL SELECT 'max' AS name, ['Python', 'SQL', 'Scala', 'Java', 'Kotlin'] AS preferred_language, 29 AS age UNION ALL SELECT 'yun' AS name, ['Python', 'SQL'] AS preferred_language, 28 AS age ) SELECT name, preferred_language, age FROM example_data- 결과는 다음과 같다
- 만약, Julia 언어를 선호하는 사람을 추출하고 싶다면 어떻게 해야할까?
- WHERE preferred_language = ‘Julia’을 사용하면 아래와 같은 오류가 발생함

- No matching signature for operator = for argument types: ARRAY
, STRING. Supported signatures: ANY = ANY at [21:7] - 이 오류는 preferred_language는 ARRAY
인데, Julia(STRING)랑 비교하려니 타입이 맞지않아 생기는 오류임
- 이런 상황에 배열을 평면화(Flatten)해서 배열에 있는 값을 펴줘야 함
- 배열을 펴줄 때 사용하는 것은 UNNEST로, Nest한 데이터를 UNNEST하게 만드는 것
- UNNEST 연산자는 ARRAY를 입력으로 받고 ARRAY의 각 요소에 대한 행이 한 개씩 포함된 테이블을 return함
- Nested는 중첩 및 반복 열 지정 Document에 더 자세한 설명을 볼 수 있음
- WHERE preferred_language = ‘Julia’을 사용하면 아래와 같은 오류가 발생함
- UNNEST() 사용하는 방법
- UNNEST한 결과와 Table을 CROSS JOIN함
SELECT alias_name.value FROM Table_A CROSS JOIN UNNEST(ARRAY 데이터) as alias_name- CROSS JOIN을 명시하지 않고 쉼표를 사용해도 동일함
SELECT alias_name.value FROM Table_A, UNNEST(ARRAY 데이터) as alias_name - 더 직관적인 이해를 위해 How to use the UNNEST function in BigQuery to analyze event parameters in Analytics 글에 나온 예시를 참고하자
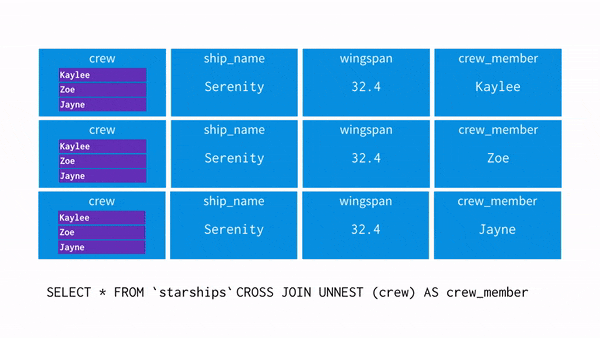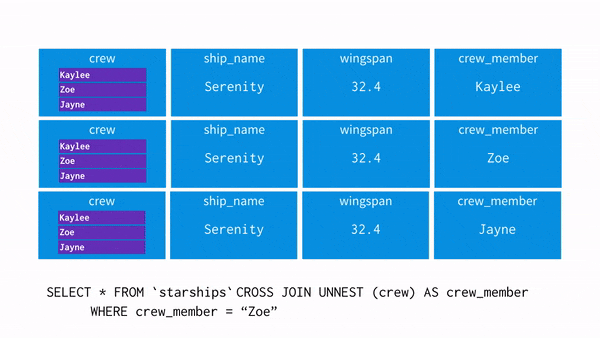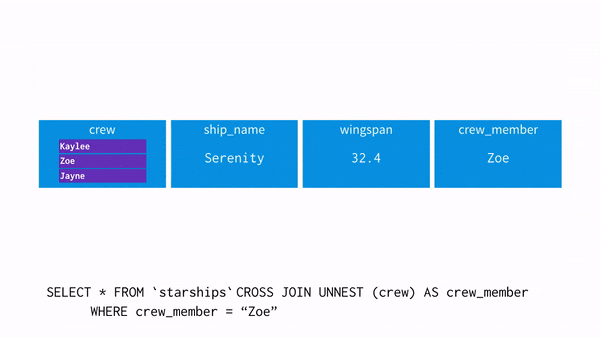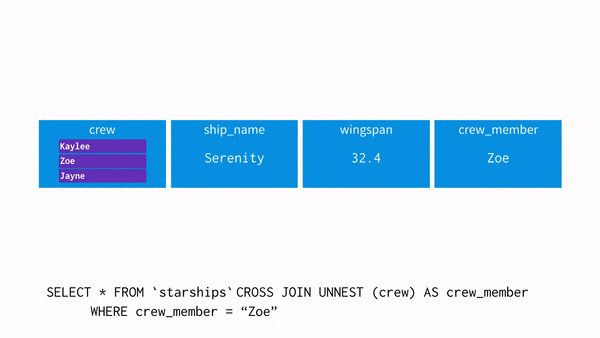
- 아래와 같은 데이터가 있다
- crew = “Zoe”를 추출하고 싶어 UNNEST를 사용
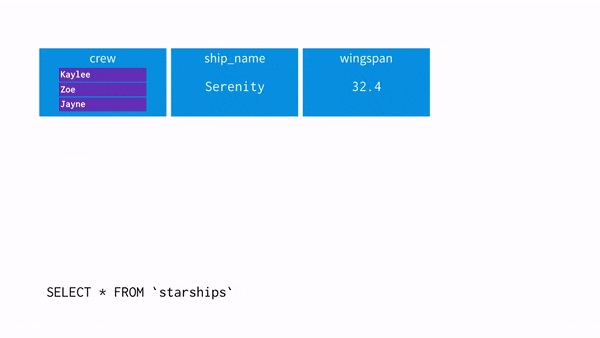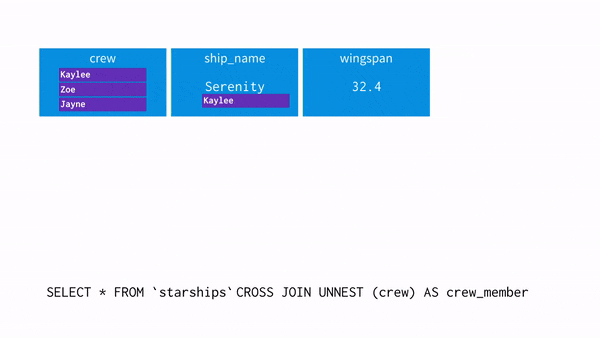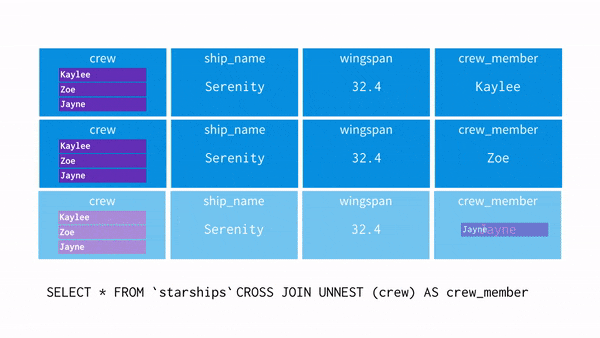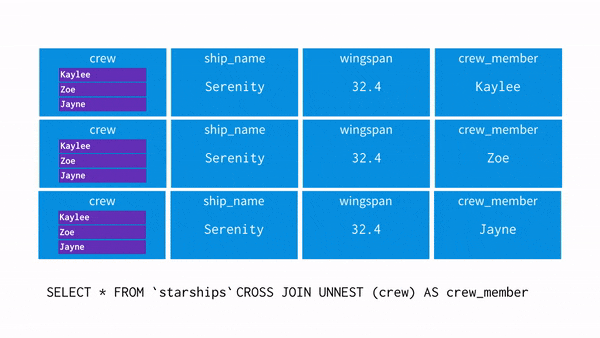
SELECT * FROM `spaceships` CROSS JOIN UNNEST(crew) as crew_member- 이 과정을 시각화하면 아래와 같음
- 이제 WHERE 조건에 crew_member = “Zoe”를 사용할 경우 어떤 흐름으로 되는지 보자
- UNNEST를 사용하면 각 행에 배열의 값을 뿌려준다(=평면화, 펴준다)
- 아래와 같은 데이터가 있다
다시 돌아와서, Julia를 선호하는 사람을 추출하는 사람을 찾기 위해 UNNEST를 사용해보자(필터링은 아직 하지말고)
WITH example_data AS( SELECT 'kyle' AS name, ['Python', 'SQL', 'R', 'Julia', 'Go'] AS preferred_language, 31 AS age UNION ALL SELECT 'max' AS name, ['Python', 'SQL', 'Scala', 'Java', 'Kotlin'] AS preferred_language, 29 AS age UNION ALL SELECT 'yun' AS name, ['Python', 'SQL'] AS preferred_language, 28 AS age ) SELECT name, prefer_lang, age FROM example_data, UNNEST(example_data.preferred_language) as prefer_lang- FROM 절을 보면 FROM example_data, UNNEST(example_data.preferred_language) as prefer_lang로 명시함
- 즉, example_data의 preferred_language ARRAY를 UNNEST로 펴주고, prefer_lang으로 alias함
- 결과는 다음과 같다
- UNNEST 전에 그냥 ARRAY 접근했던 경우와 비교하자
- 이제 UNNEST 전 후에 어떻게 되는지 주의깊게 보자. 행이 왼쪽은 3, 오른쪽은 12!

- FROM 절을 보면 FROM example_data, UNNEST(example_data.preferred_language) as prefer_lang로 명시함
UNNEST 하고 prefer_lang = ‘Julia’ 조건을 준 쿼리는 아래와 같음
WITH example_data AS( SELECT 'kyle' AS name, ['Python', 'SQL', 'R', 'Julia', 'Go'] AS preferred_language, 31 AS age UNION ALL SELECT 'max' AS name, ['Python', 'SQL', 'Scala', 'Java', 'Kotlin'] AS preferred_language, 29 AS age UNION ALL SELECT 'yun' AS name, ['Python', 'SQL'] AS preferred_language, 28 AS age ) SELECT name, prefer_lang, age FROM example_data, UNNEST(example_data.preferred_language) as prefer_lang WHERE prefer_lang = 'Julia'



응용
- ARRAY에 특정 값이 있는지 확인하고 싶은 경우
- WHERE 절에서 UNNEST로 풀고, IN 사용
- Scala를 선호하는 사람을 찾고 싶은 경우
WITH example_data AS( SELECT 'kyle' AS name, ['Python', 'SQL', 'R', 'Julia', 'Go'] AS preferred_language, 31 AS age UNION ALL SELECT 'max' AS name, ['Python', 'SQL', 'Scala', 'Java', 'Kotlin'] AS preferred_language, 29 AS age UNION ALL SELECT 'yun' AS name, ['Python', 'SQL'] AS preferred_language, 28 AS age ) SELECT name, preferred_language, age FROM example_data WHERE 'Scala' IN UNNEST(example_data.preferred_language)- 맨 아래에 WHERE ‘Scala’ IN UNNEST(example_data.preferred_language) 이렇게 필터링함

- ARRAY에 특정 조건이 일치하는 값을 검색하고 싶은 경우
- EXISTS 사용
- IN 조건이 여러개 있는 경우에도 사용 가능
- Go나 Scala를 선호하는 사람을 찾고싶은 경우
WITH example_data AS( SELECT 'kyle' AS name, ['Python', 'SQL', 'R', 'Julia', 'Go'] AS preferred_language, 31 AS age UNION ALL SELECT 'max' AS name, ['Python', 'SQL', 'Scala', 'Java', 'Kotlin'] AS preferred_language, 29 AS age UNION ALL SELECT 'yun' AS name, ['Python', 'SQL'] AS preferred_language, 28 AS age ) SELECT name, preferred_language, age FROM example_data WHERE EXISTS ( SELECT * FROM UNNEST(example_data.preferred_language) as prefer_lang WHERE prefer_lang IN ('Go','Scala') )- 아래에 EXISTS ~ 부분 참고

- EXISTS 사용
- Firebase Analytics에 저장된 데이터 추출하기
- Firebase의 BigQuery Export Document
- BigQuery에서 Firebase 데이터 샘플을 제공함. https://bigquery.cloud.google.com/dataset/firebase-public-project:analytics
- 스키마는 다음과 같음
- 데이터를 미리보면 다음과 같음
- 우리가 아까 봤던 ARRAY보다 조금 더 복잡함
- event_params는 유저가 행동한 이벤트가 저장되고, user_properties는 유저의 고유 정보가 저장됨
- 두 RECORD 모두 형태는 비슷하지만, 저장된 파라미터가 다르기 때문에 2개의 UDF를 만들어서 사용함
- 회사라면 Persistent UDF 만들어서 활용하면 됨
- UDF에 대해 궁금한 경우 BigQuery UDF 사용하기 참고
# UDF for event parameters CREATE TEMP FUNCTION paramValueByKey(k STRING, params ARRAY<STRUCT<key STRING, value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, double_value FLOAT64 >>>) AS ( (SELECT x.value FROM UNNEST(params) x WHERE x.key=k) ); # UDF for user properties CREATE TEMP FUNCTION propertyValueByKey(k STRING, properties ARRAY<STRUCT<key STRING, value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, double_value FLOAT64, set_timestamp_micros INT64 >>>) AS ( (SELECT x.value FROM UNNEST(properties) x WHERE x.key=k) ); SELECT user_pseudo_id, event_name, event_timestamp, propertyValueByKey('num_levels_available', user_properties).string_value AS num_levels_available, paramValueByKey('board', event_params).string_value AS board, paramValueByKey('firebase_screen_class', event_params).string_value as firebase_screen_class from `firebase-public-project.analytics_153293282.events_20181003` LIMIT 10- 아래의 결과가 나타남
- screen_view event_name에 board가 null인 이유는 screen_view 이벤트엔 board 파라미터가 없기 때문!



정리
- BigQuery ARRAY : 데이터 유형이 동일한 값으로 구성된 목록
- BigQuery STRUCT : 각각 유형(필수)과 필드 이름(선택사항)이 있는 정렬된 필드의 컨테이너
- ARRAY을 평면화(Flatten)하고 싶은 경우 UNNEST 사용
- UNNEST 전/후를 보면 이해하기 수월
- 과정이 이해가 안되면 GIF 참고!
- Firebase Analytics에 저장되는 데이터는 UDF를 만들어서 활용!
Reference
- How to use the UNNEST function in BigQuery to analyze event parameters in Analytics
- BigQuery Tip: The UNNEST Function
- BigQuery 중첩 및 반복 열 지정
- BigQuery 배열 다루기
- Google BigQuery 쉽게 쓰게 하기 (feat. ARRAY) : 갓꼬젯님의 글..!
카일스쿨 유튜브 채널을 만들었습니다. 데이터 분석, 커리어에 대한 내용을 공유드릴 예정입니다.
PM을 위한 데이터 리터러시 강의를 만들었습니다. 문제 정의, 지표, 실험 설계, 문화 만들기, 로그 설계, 회고 등을 담은 강의입니다
이 글이 도움이 되셨거나 의견이 있으시면 댓글 남겨주셔요.
